[Kaggle] Titanic 생존자 예측 (1) EDA
Kaggle에서 데이터 분석 입문자를 위한 튜토리얼이라고 볼 수 있는 Titanic - Machine Learning from Disaster 을 Python으로 진행하는 과정을 포스팅 할 것이다.

배경지식
- RMS 타이타닉호는 1912년 4월 10일 영국의 사우샘프턴을 떠나 미국의 뉴욕으로 향하던 첫 항해 중에 4월 15일 빙산과 충돌하여 침몰하였다. 타이타닉호의 침몰로 1,514명이 사망하였다.
목표
- 생존유무가 포함된 탑승객의 학습 데이터 정보를 분석하고 그 정보를 바탕으로 기계학습을 진행하여 테스트 데이터의 탑승객 생존유무를 예측
1. 탐색적 데이터 분석(EDA)
1.1. 데이터 확보
- 본 포스팅에서 사용한 데이터는 Kaggle에서 다운받을 수 있습니다.
- 각 탑승객의 신상정보와 생존유무가 담긴
Train데이터와 예측할 탑승객 정보가 담긴Test데이터를 csv파일로 제공합니다.
1.2. Data Dictionary
- Survived - 생존유무, target 값. (0 = 사망, 1 = 생존)
- Name - 탑승객 성명
- Pclass - 티켓 클래스. (1 = 1st, 2 = 2nd, 3 = 3rd)
- Sex - 성별
- Age - 나이(세)
- SibSp - 함께 탑승한 형제자매, 배우자 수 총합
- Parch - 함께 탑승한 부모, 자녀 수 총합
- Embarked - 탑승 항구
- Fare - 탑승 요금
- Ticket - 티켓 넘버
- Cabin - 객실 넘버
1.3. 데이터 확인
train.csv를 불러옵니다.
1 2 3 4 | import pandas as pd train_dt = pd.read_csv('train.csv') train_dt.head() |

- 데이터가 모두 존재하는지 확인합니다.
1 | train_dt.info() |
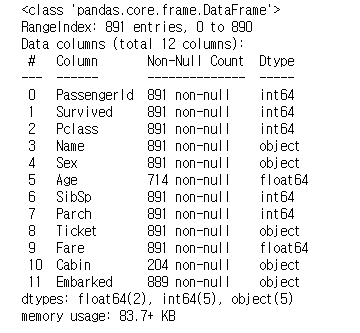
Age,Cabin,Embarked에 결측치가 있는 것을 확인할 수 있습니다.- 특히
Cabin의 결측치가 상당히 많이 존재합니다. Feature로 사용하기에는 불가능 할 것 같습니다.
- 특히
PassengerId는 승객의 번호이므로 생존유무와 연광성이 없어보입니다.
1.4. Feature Exploration
- 각 Feature 별로 분석을 진행해 봅니다.
- 분석에 사용 할 시각화 라이브러리를 불러옵니다.
- 개인적으로
seaborn을 좋아하기 때문에 스타일도 맞춰줍니다. - 한글도 사용하기 위해 설정 해줍니다.
1 2 3 4 5 6 7 8 9 10 11 | %matplotlib inline import matplotlib.pyplot as plt import seaborn as sns #시각화 준비 plt.style.use('seaborn') sns.set(font_scale=2) # 한글 사용 준비 plt.rcParams['font.family']='NanumGothic' |
1.4.1. Survived
- 생존유무를 나타내는 Feature 입니다.
- 전체 데이터의 생존유무를 수치화 해봅니다.
- 0은 사망, 1은 생존을 나타냅니다.
1 | train_dt['Survived'].value_counts() |

- 수치상으로 사망자의 수가 더 많은 것을 알 수 있습니다.
- 좀 더 한눈에 볼 수 있게 pie 와 bar plot을 사용해 시각화를 합니다.
1 2 3 4 5 6 7 8 9 10 11 12 | fig, ax = plt.subplots(1, 2, figsize=(14,5)) labels = ['사망', '생존'] # Pie Plot train_dt['Survived'].value_counts().plot.pie(ax=ax[0], explode=[0,0.1], shadow=True, autopct='%1.1f%%', labels=labels) ax[0].set(ylabel='') # Count Plot sns.countplot(data=train_dt, x='Survived', ax=ax[1]) ax[1].set(xlabel='', xticklabels=labels) plt.show() |
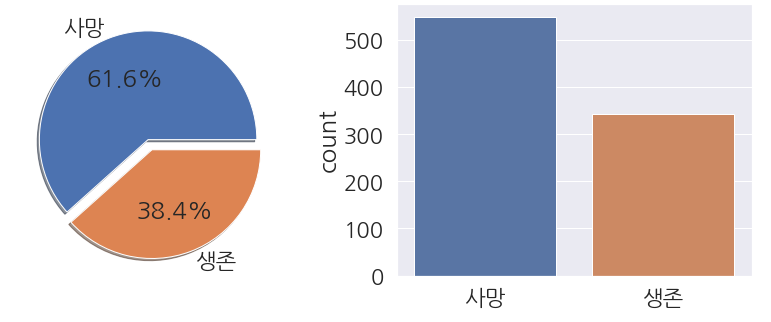
- 사망자의 비율이 엄청 높습니다.
- 탑승객의 다른 정보와 생존유무가 어떠한 상관관계가 있는지 알아봅시다.
1.4.2. Name
- 탑승객의 이름을 나타내는 Feature 입니다.
- 설마 이름 때문에 생존유무가 갈리지는 않겠지만 데이터를 살펴봅니다.
1 | train_dt['Name'].unique() |

- 어…음…네.. 이건 그래프로 안(못) 그립니다.
- 데이터를 잘 보니 호칭(Mr, Mrs, Miss …) 이 보입니다.
- 성별을 구분지을 수 있는 요소이므로 잘 정제한다면 사용할 수 있을 것 같습니다.
1.4.3. Pclass
- 티켓의 클래스(등급)를 나타내는 Feature 입니다.(1, 2, 3 등석 개념)
- 1, 2, 3 클래스로 나누어져있습니다. (1등석이 가장 비싼 자리겠죠?)
- 클래스별로 인원의 비율을 살펴봅니다.
1 | train_dt['Pclass'].value_counts() |

- 숫자로 보면 크게 와닿지 않습니다.
- 시각화를 해봅니다.
1 2 3 4 5 | fig, ax = plt.subplots(figsize=(7,5)) sns.countplot(data=train_dt, x='Pclass', ax=ax) plt.show() |
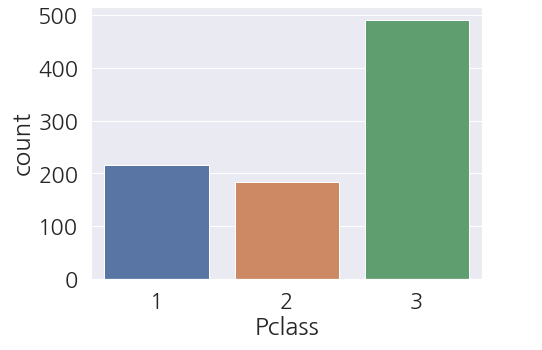
- 1, 2 클래스에 비해 3 클래스가 많은 것을 볼 수 있습니다.
- 이제
Pclass와Survived가 어떤 관계가 있는지 알아봅시다. - 클래스 별로 생존율을 구합니다.(
Survived가 0과 1로 주어지므로 간단하게 구할 수 있음)
1 2 | #Groupby를 이용한 Pclass에 따른 Survived의 평균 train_dt[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False) |
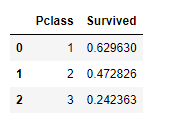
- 1, 2, 3 클래스 순으로 생존율이 높은 것을 알 수 있습니다.
- 그래프로도 알아봅시다.
1 2 3 4 5 6 7 8 9 | fig, ax = plt.subplots(figsize=(6,6)) sns.countplot(data=train_dt, x='Pclass', hue='Survived', ax=ax) #범례 한글로 변경 labels=['사망', '생존'] ax.legend(labels=labels) plt.show() |
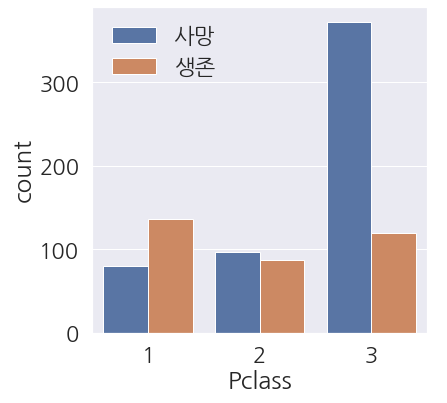
- 가장 눈에 띄에 들어오는 부분은 3 클래스 입니다.
- 3 클래스 탑승객들의 사망인원이 상당한 것을 볼 수 있습니다.
- 좀 더 상세하게 알아보기 위해 Pie Plot도 그려봅시다.
1 2 3 4 5 6 7 8 9 10 11 12 | fig, ax = plt.subplots(1,2,figsize=(10,4), constrained_layout=True) #Survived 가 0인 데이터를 이용한 Pie Plot train_dt[train_dt['Survived'] == 0]['Pclass'].value_counts().sort_index().plot.pie(ax=ax[0], shadow=True, autopct='%1.1f%%') ax[0].set(ylabel='', title='사망 - Pclass') #Survived 가 1인 데이터를 이용한 Pie Plot train_dt[train_dt['Survived'] == 1]['Pclass'].value_counts().sort_index().plot.pie(ax=ax[1], shadow=True, autopct='%1.1f%%') ax[1].set(ylabel='', title='생존 - Pclass') plt.show() |
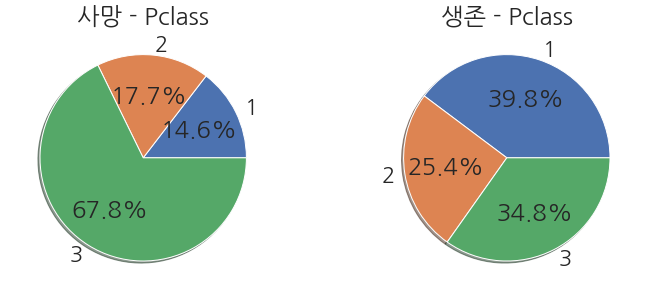
- 사망한 탑승객 그래프에서 3 클래스의 비율이 67.8%나 된다는 것을 볼 수 있습니다.
- 번외로 클래스별로 탑승가격을 비교해 봅시다.
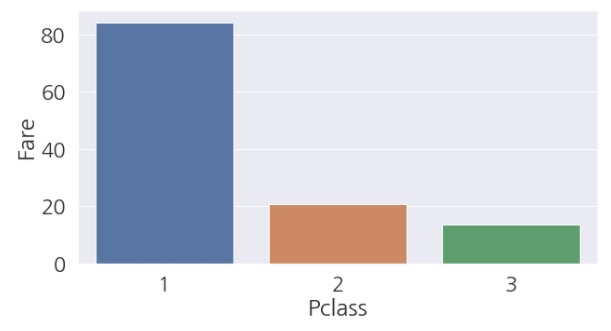
- 생존인원이 가장 많은 1 클래스의 가격이 어마무시 합니다.
역시 돈이 많아야..
1.4.4. Sex
- 성별을 나타내는 Feature 입니다.
- male(남성), female(여성)으로 나누어져있습니다.
- 그래프를 그려 비율을 살펴봅니다.
1 2 3 4 5 6 7 8 9 10 11 12 | fig, ax = plt.subplots(1,2,figsize=(14,5)) labels = ['남성', '여성'] # Pie Plot train_dt['Sex'].value_counts().plot.pie(ax=ax[0], shadow=True, autopct='%1.1f%%', labels=labels) ax[0].set(ylabel='') # Count Plot sns.countplot(data=train_dt, x='Sex', ax=ax[1]) ax[1].set(xticklabels=labels, xlabel='') plt.show() |
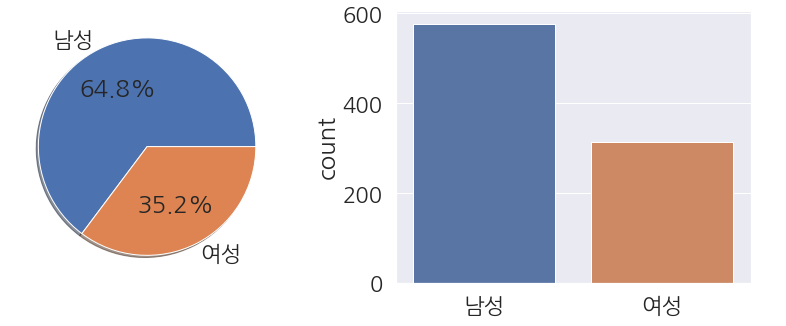
- 여성 탑승객보다 남성 탑승객이 더 많습니다.
Sex와Survived가 관련이 있는지 살펴봅니다.
1 2 | #Groupby를 이용한 Sex에 따른 Survived의 평균 train_dt[['Sex', 'Survived']].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False) |
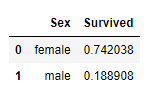
- 음? 생존율의 차이가 심합니다.
1 2 3 4 5 6 7 8 9 10 11 | fig, ax = plt.subplots(figsize=(6,6)) sns.countplot(data=train_dt, x='Sex', hue='Survived', ax=ax) ax.set(xticklabels=['남성', '여성'], xlabel='') #범례 한글로 변경 labels=['사망', '생존'] ax.legend(labels=labels) plt.show() |
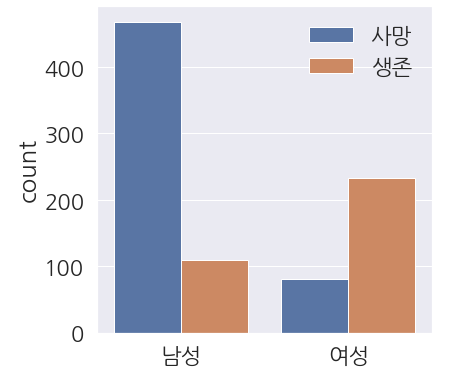
- 남성의 생존율이 굉장히 낮은 것을 볼 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 | fig, ax = plt.subplots(1,2,figsize=(10,6), constrained_layout=True) labels = ['여성', '남성'] #Survived 가 0인 데이터를 이용한 Pie Plot train_dt[train_dt['Survived'] == 0]['Sex'].value_counts().sort_index().plot.pie(ax=ax[0], shadow=True, autopct='%1.1f%%', labels=labels) ax[0].set(ylabel='', title='사망 - Sex') #Survived 가 1인 데이터를 이용한 Pie Plot train_dt[train_dt['Survived'] == 1]['Sex'].value_counts().sort_index().plot.pie(ax=ax[1], shadow=True, autopct='%1.1f%%', labels=labels) ax[1].set(ylabel='', title='생존 - Sex') plt.show() |
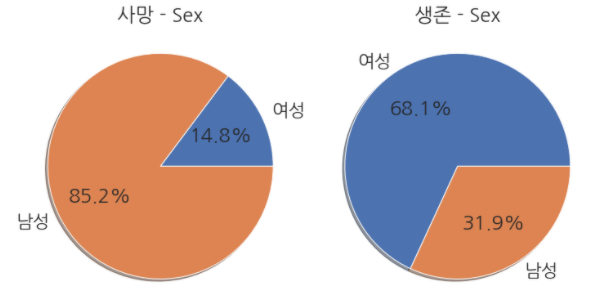
- 생존-사망을 나누어 보니 확연한 차이가 보입니다.
- 남자 탑승객이 더 많기는 했지만 엄청난 사망률을 보입니다.
- 여성은 상대적으로 많은 인원이 생존한 것을 볼 수 있습니다.
- 위급 상황에서 여성을 우선으로 대피시켰을 것으로 추측해봅니다.
Lady First?
1.4.5. Age
- 나이를 나타내는 Feature 입니다.
- 앞서 살펴 보았듯이
Age는 결측값을 가지고 있습니다. - 나이는 수치형으로 주어졌기 때문에 분포를 볼 수 있는 그래프를 이용합니다.
Seaborn에Dist Plot이라고 하는 분포를 한눈에 알아 볼 수 있는 그래프를 사용합니다.
1 2 3 4 5 | fig, ax = plt.subplots(figsize=(10,6)) sns.distplot(train_dt['Age'], bins=25, ax=ax) plt.show() |
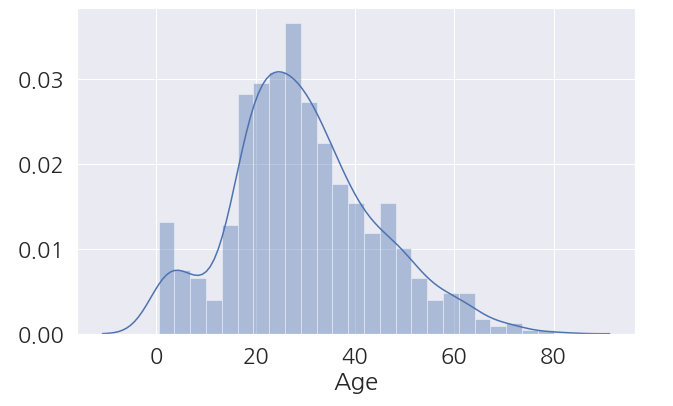
-
탑승객 나이 분포를 보니 20~40대가 가장 많은 것을 볼 수 있습니다.
-
Age 와 Survived 의 관계를 찾기 위해 조금 복잡하지만 생존율 그래프를 그려봅시다.
-
N살의 생존 인원수를 N살의 전체 인원수로 나누면 됩니다.
쉽죠?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # 생존율을 입력받을 List 생성 age_range_survival_ratio = [] # 1살 부터 생존율 구하기 for i in range(1,80): age_range_survival_ratio.append(train_dt[train_dt['Age'] < i]['Survived'].sum() / len(train_dt[train_dt['Age'] < i]['Survived'])) plt.figure(figsize=(7,7)) plt.plot(age_range_survival_ratio) plt.title('나이별 생존율') plt.ylabel('생존율') plt.xlabel('나이') plt.show() |
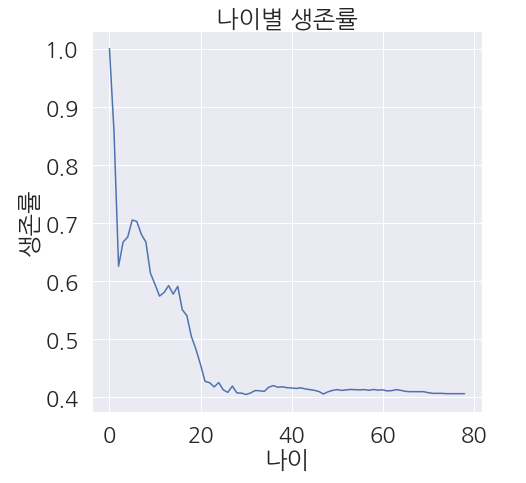
- 20세 이하의 생존율이 높습니다.
- 위에서 20~40대가 많았었습니다. 하지만 생존율은 매우 낮습니다.
- 50세 이상은 인원수가 적기 때문에 생존율이 큰 의미를 가질지는 모르겠습니다.
1.4.6. SibSp
- 함께 탑승한 형제자매, 배우자의 총합을 나타내는 Feature 입니다.
- 본인을 포함하고 있지 않습니다.
- 그래프 확인부터 합시다.
1 2 3 4 5 | fig, ax = plt.subplots(figsize=(5,6)) sns.countplot(data=train_dt, x='SibSp') plt.show() |
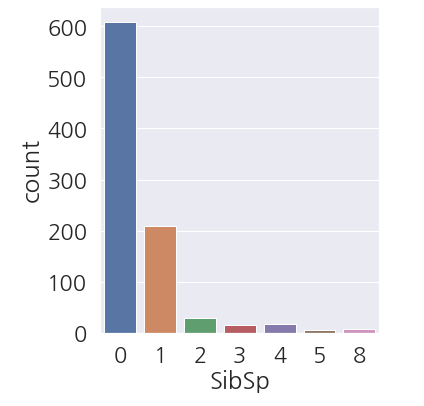
- **0(혼자 탄 사람)**이 많은게 한눈에 보입니다.
- 생존유무와 관련이 있나 살펴봅니다.
1 2 | #Groupby를 이용한 SibSp에 따른 Survived의 평균 train_dt[['SibSp', 'Survived']].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False) |
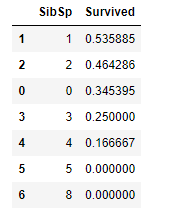
- 동승자가 1명 있는 탑승자가 생존율이 가장 높습니다.
- 그래프로 확인해 봅니다.
1 2 3 4 5 6 7 8 9 | fig, ax = plt.subplots(figsize=(10,6)) sns.countplot(data=train_dt, x='SibSp', hue='Survived', ax=ax) #범례 한글로 변경 labels=['사망', '생존'] ax.legend(labels=labels) plt.show() |
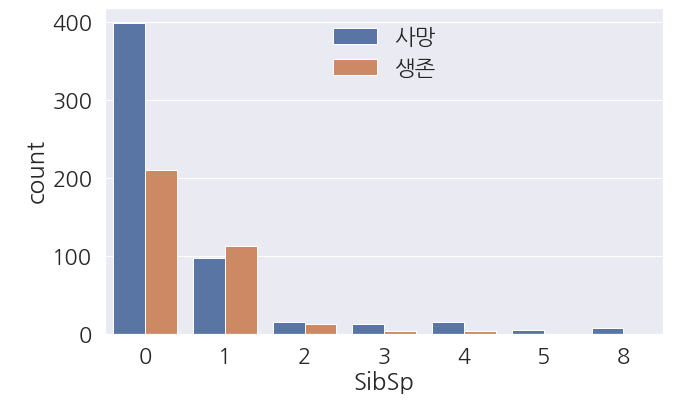
- 0(혼자 탄 사람) 이 인원이 많아서 그런지 사망과 생존수가 많습니다.
- 0(혼자 탄 사람) 의 생존수 보다는
- 동승자가 있는 탑승객은 표본이 많지 않아서 유의미한 관계를 찾기는 어려워 보입니다.
1.4.7. Parch
- 합께 탑승한 부모, 자녀 수 총합을 나타내는 Feature 입니다.
- 앞서 살펴본
SibSp와 유사한 데이터 같습니다. - 그래프를 그려봅시다.
1 2 3 4 5 | fig, ax = plt.subplots(figsize=(5,6)) sns.countplot(data=train_dt, x='Parch') plt.show() |
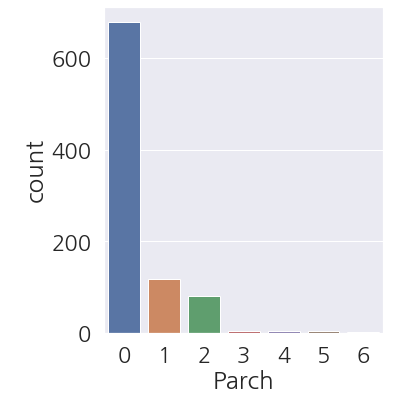
-
오우.. 방금 전에 본 그래프와 비슷해 보입니다.
-
혼자 탄 사람이 많습니다.
-
생존율을 확인해 봅시다.
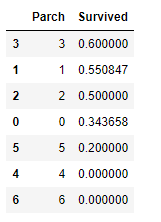
- 역시나 0(혼자 탄 사람) 은 생존율이 높지 않은 것을 볼 수 있습니다.
- 어느정도 예상은 되지만 그래프로 확인해 봅시다.
1 2 3 4 5 6 7 8 9 | fig, ax = plt.subplots(figsize=(10,6)) sns.countplot(data=train_dt, x='Parch', hue='Survived', ax=ax) #범례 한글로 변경 labels=['사망', '생존'] ax.legend(labels=labels) plt.show() |
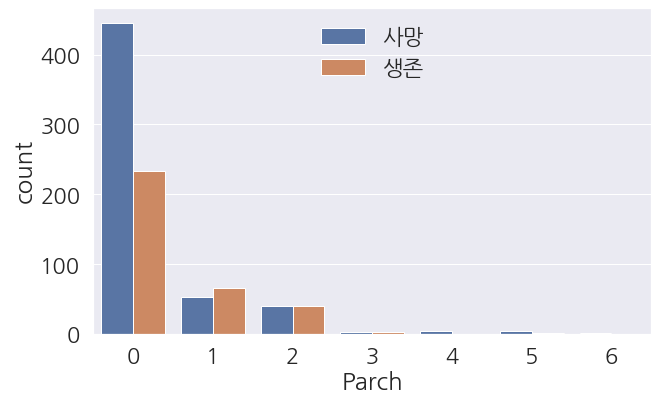
그만 확인해 보도록 합시다- 앞서 살펴본
SibSp와 아주 흡사한 그래프를 나타내고 있습니다. SibSp와Parch는 하나의 데이터로 합쳐서 사용할 수 있을 것 같습니다.
1.4.8. Embarked
- 탑승한 항구를 나타내는 Feature 입니다.
- S항구, C항구, Q항구 3종류의 항구가 있으며 결측값이 존재합니다.
- 그래프로 살펴봅니다.
1 2 3 4 5 6 7 8 | fig, ax = plt.subplots(1,2,figsize=(14,5)) train_dt['Embarked'].value_counts().plot.pie(ax=ax[0], shadow=True, autopct='%1.1f%%') ax[0].set(title='Embarked', ylabel='') sns.countplot(data=train_dt, x='Embarked', ax=ax[1]) plt.show() |
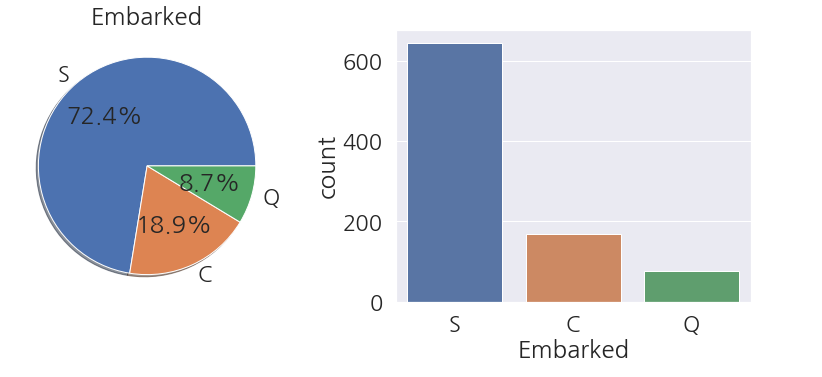
-
S항구의 탑승객이 제일 많은 것을 확인 할 수 있습니다.
-
항구와 생존유무가 관계가 있나 살펴봅니다.
1 2 | #Groupby를 이용한 Embarked에 따른 Survived의 평균 train_dt[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False) |
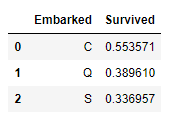
- 음…그래프를 한번 봅시다.
1 2 3 4 5 6 7 8 9 | fig, ax = plt.subplots(figsize=(10,6)) sns.countplot(data=train_dt, x='Embarked', hue='Survived', ax=ax) #범례 한글로 변경 labels=['사망', '생존'] ax.legend(labels=labels) plt.show() |
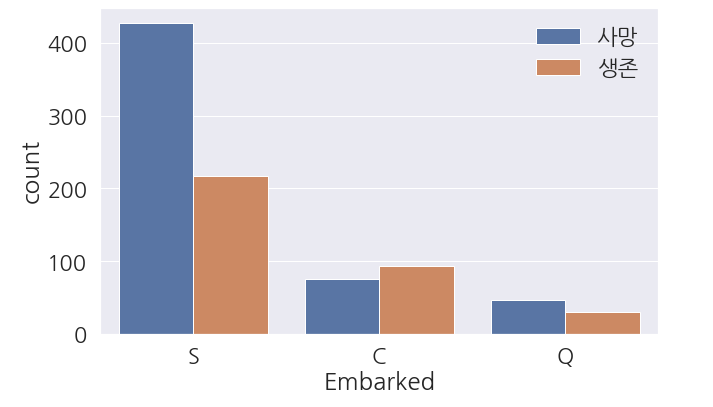
- 상식적으로 탑승 항구와 생존유무는 관련이 없을 거 같았지만, 이상하게 S항구 탑승객들의 사망률이 높습니다.
저주받은 S항구?- 혹시 항구마다 탑승객의 클래스가 다른지 확인해 봅니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # Pclass 별로 데이터를 나눠줍니다 Pclass1 = train_dt[train_dt['Pclass']==1]['Embarked'].value_counts() Pclass2 = train_dt[train_dt['Pclass']==2]['Embarked'].value_counts() Pclass3 = train_dt[train_dt['Pclass']==3]['Embarked'].value_counts() # DataFrame으로 만들어서 그래프 fig, ax = plt.subplots(figsize=(10,7)) df = pd.DataFrame([Pclass1, Pclass2, Pclass3]) df.index = ['1st class','2nd class','3rd class'] df.plot(kind='bar', stacked=True, ax=ax) # xlabel 회전 plt.xticks(rotation=45) plt.show() |
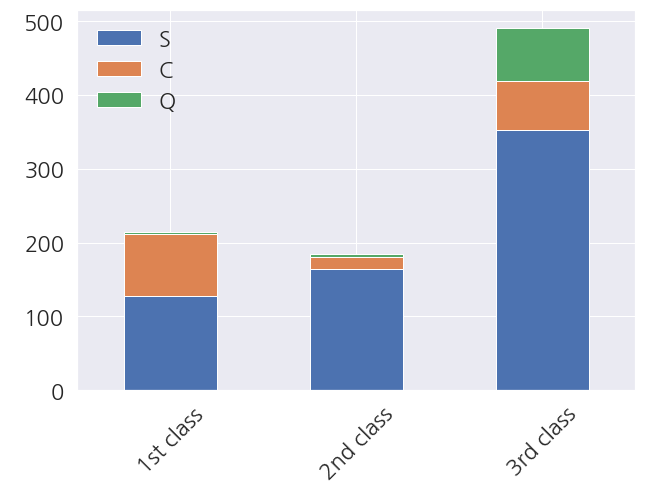
- 이런.. S항구에서 탄 탑승객 중 3 클래스가 많은 것을 알 수 있습니다.
- S항구의 사망률이 높은 이유와 연관지을 수 있을 것 같습니다.
- 혹시나 하는 마음에 동승자의 유무와도 연관이 있나 살펴봅니다.
1 2 3 4 5 6 7 8 9 10 | fig, ax = plt.subplots(1,2,figsize=(13,6), constrained_layout=True) sns.countplot(data=train_dt, x='SibSp', hue='Embarked', ax=ax[0]) sns.countplot(data=train_dt, x='Parch', hue='Embarked', ax=ax[1]) # 범례 위치조정 ax[0].legend(loc='upper right') ax[1].legend(loc='upper right') plt.show() |
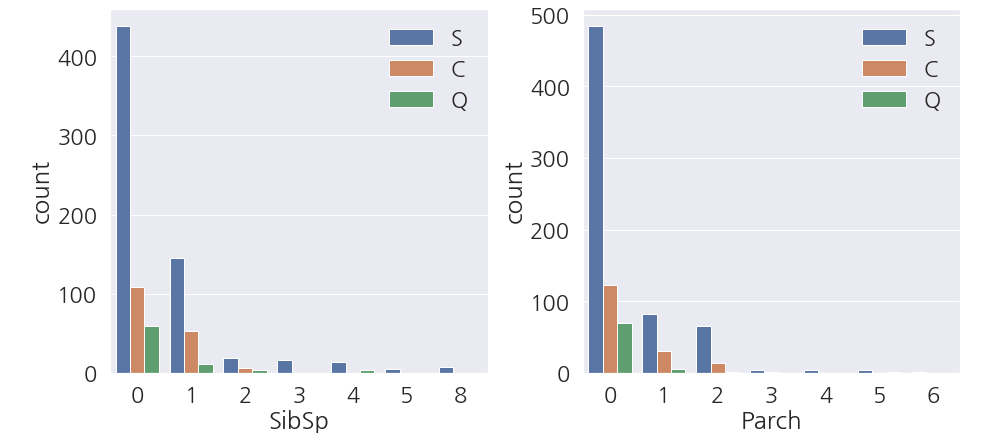
- 앗.. S항구에 혼자 탄 사람이 많습니다.
- 정말 혹시나 하는 마음에 혼자 탄 사람이 3 클래스에 많은지도 확인해 봅니다.
1 2 3 4 5 6 7 8 9 10 | fig, ax = plt.subplots(1,2,figsize=(13,6), constrained_layout=True) sns.countplot(data=train_dt, x='SibSp', hue='Pclass', ax=ax[0]) sns.countplot(data=train_dt, x='Parch', hue='Pclass', ax=ax[1]) # 범례 위치조정 ax[0].legend(loc='upper right') ax[1].legend(loc='upper right') plt.show() |
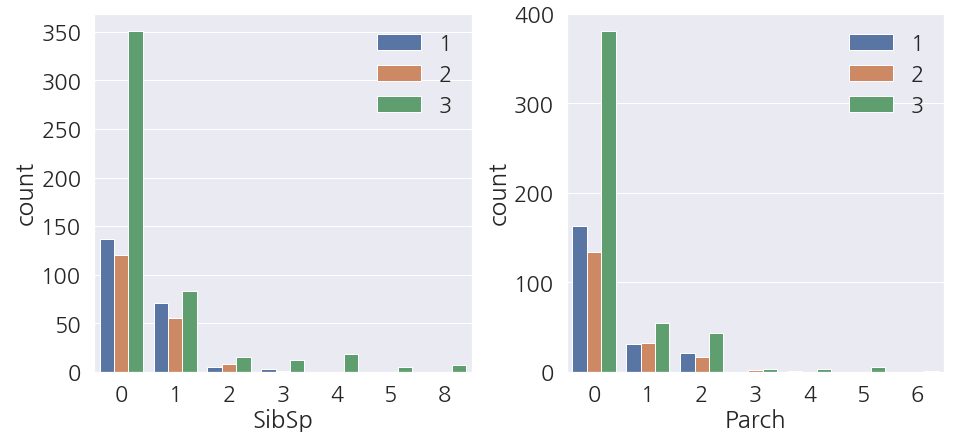
- 정말 슬픈 사실을 알게 됐습니다.
- S항구에서 나홀로 3 클래스에 탄 탑승객의 사망률이 높다는 것 입니다.
1.4.9. Fare
- 탑승 요금을 나타내는 Feature 입니다.
- 요금은
Pclass와 연관이 있을 것으로 추측해봅니다. - 탑승 요금의 분포를 살펴봅니다.
1 2 3 4 5 6 | fig, ax = plt.subplots(figsize=(10,6)) # 분포확인 sns.distplot(train_dt['Fare'], bins=25, ax=ax) plt.show() |
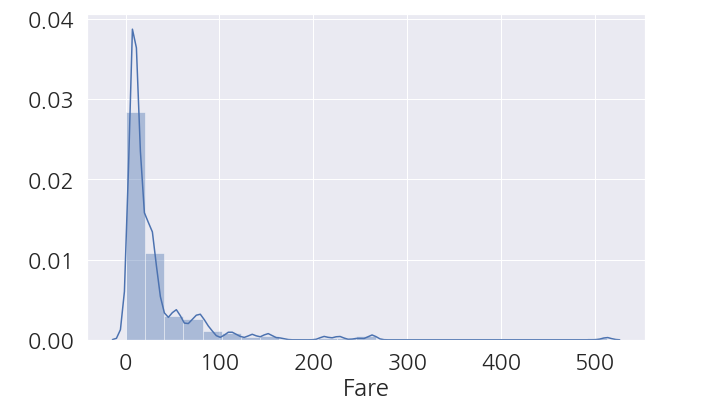
- 3 클래스 탑승객이 많아서 그런지 낮은 가격대에 분포돼 있는 것을 볼 수 있습니다.
- 앞서
Fare와Pclass의 관계는 그래프로 확인했습니다. - 그래도 요금이 생존유무와 관련 있는지 확인해 봅시다.
1 2 3 4 5 6 7 8 9 10 11 | fig, ax = plt.subplots(figsize=(10,6)) # 분포 확인 sns.kdeplot(train_dt[train_dt['Survived']==1]['Fare'], ax=ax) sns.kdeplot(train_dt[train_dt['Survived']==0]['Fare'], ax=ax) # 가장 높은 가격까지 범위 확대 ax.set(xlim=(0, train_dt['Fare'].max())) ax.legend(['생존', '사망']) plt.show() |
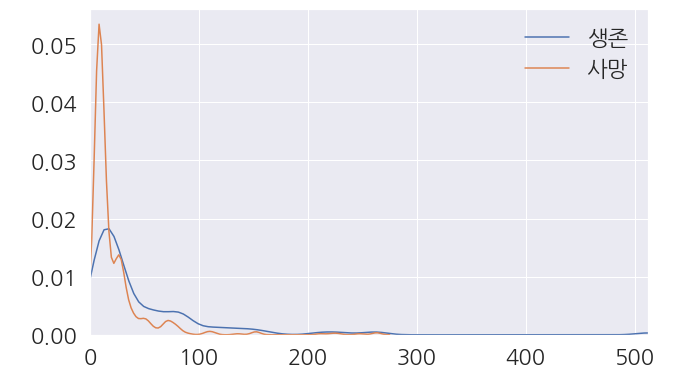
- 어느정도 패턴이 보이는 것 같습니다.
S항구에서 탄 나홀로 3등석 탑승객의 비극
1.4.10. Ticket
- 티켓 번호를 나타내는 Feature 입니다.
- 티켓 번호로 클래스나 가격과 같은 정보를 얻을 수 있는지 확인해 봅니다.
1 | train_dt['Ticket'].unique() |

- …..?? 네 이건 아무리 봐도 잘 모르겠습니다.
- 티켓 번호에 대한 패턴을 찾기 어려워 보입니다.
1.4.11. Cabin
- 객실 번호를 나타내는 Feature 입니다.
- 총 891개의 데이터중 204개의 데이터만 보유하고 있습니다.
- 결측치가 너무 많고 느낌이 좋지 않습니다.
1 | train_dt['Cabin'].unique() |

- 음… 알파벳으로 시작하고 숫자가 붙어있는 구조입니다.
- 하지만 결측값이 너무 많고 패턴파악이 쉽지 않아 사용하기는 어려워 보입니다.
- 이렇게 모든 Feature를 살펴봤습니다.
- 데이터에서 시각화를 통해 패턴을 찾아 상관관계를 파악했습니다.
- 정보를 얻을 수 있는 데이터와 아닌 데이터를 구별 지었습니다.
- 다음 포스팅에서는 학습을 위한 데이터로 만드는 과정인 Feature Engineering 을 다루겠습니다.