[Kaggle] Titanic 생존자 예측 (2) Feature Engineering
이전 포스팅에서 데이터를 다양한 각도에서 관찰하고 이해하는 탐색적 데이터 분석(EDA)를 진행했습니다. 이번 포스팅에서는 기계학습을 위해 적절한 Feature들을 선택 및 정제하는 과정을 진행하겠습니다.
2. Feature Engineering
- Feature 의 특징을 떠올리며 차근차근 살펴봅시다.
- Model은 숫자로 표현된 Feature를 입력으로 사용한다.
- 문자열 값을 숫자로 변환하는 작업을 합니다.
- Train 데이터와 Test 데이터를 불러옵니다.
- Train 과 Test 를 한번에 변환하기 위해 List에 담아줍니다.
1 2 3 4 5 6 7 8 | import pandas as pd # Train 과 Test 데이터를 준비 train_dt = pd.read_csv('train.csv') test_dt = pd. read_csv('test.csv') # 한번에 처리하기 위한 작업 data_train_test = [train_dt, test_dt] |
2.1. Name
- 탑승객의 이름입니다.

- 영어 이름에는 Mr, Mrs, Miss, Ms.. 등과 같은 호칭이 붙습니다.
- 호칭 뒤에는 .(마침표)가 붙으니 정규식을 이용해
Title에 추출합니다
1 2 3 4 5 | # 정규식을 이용해 Title로 호칭 추출 for data in data_train_test: data['Title'] = data['Name'].str.extract('([A-Za-z]+)\.', expand=False) train_dt.head() |
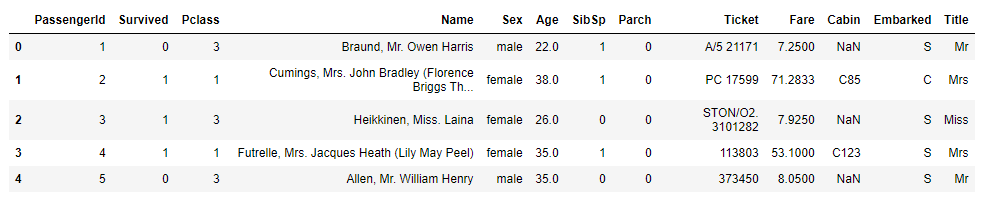
- 추출이 잘됐습니다.
- Pandas 의 crosstab 을 사용해
Title별Sex의 분포를 살펴봅니다.
1 2 3 4 5 | # Train 데이터 Title의 성별 분포 pd.crosstab(train_dt['Title'], train_dt['Sex']) # Test 데이터 Title의 성별 분포 pd.crosstab(test_dt['Title'], test_dt['Sex']) |
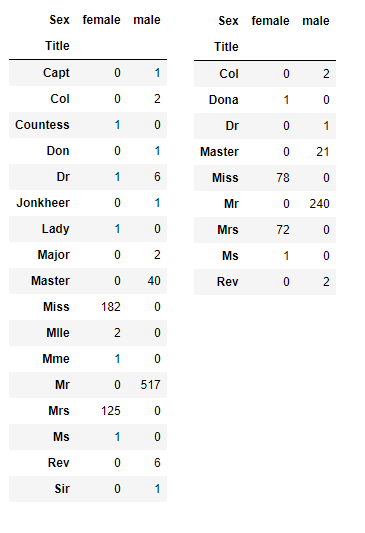
- 호칭을 검색해보면서 어떤 용도로 쓰이는지 찾아봅니다.
- Mlle, Ms 는 Miss로 Mme, Lady, Dona는 Mrs로 Don은 Mr로 변경합니다.
- 가장 많이 쓰이는 Mr, Mrs, Miss, Master와 나머지를 포함한 Others 로 그룹화합니다.
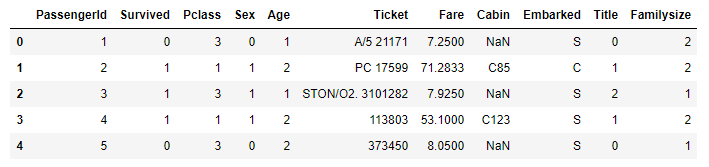
1 2 3 4 5 6 7 8 9 | # Title 매핑작업 for data in data_train_test: data['Title'] = data['Title'].replace(['Capt', 'Col', 'Countess', 'Dr', 'Jonkheer', 'Major', 'Rev', 'Sir'], 'Others') data['Title'] = data['Title'].replace(['Mlle', 'Ms'], 'Miss') data['Title'] = data['Title'].replace('Don', 'Mr') data['Title'] = data['Title'].replace(['Mme', 'Lady', 'Dona'], 'Mrs') # Title 별 생존율 train_dt[['Title', 'Survived']].groupby(['Title'], as_index=False).mean().sort_values(by='Survived', ascending=False) |
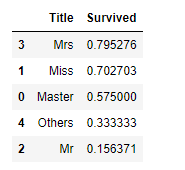
Title별로 생존율을 보니 확연한 차이가 보입니다.Name을Title로 대체 했으니 필요없는Name은 지워줍니다.
1 2 3 4 5 | # Name 삭제 for data in data_train_test: data.drop('Name', inplace=True, axis=1) train_dt.head() |
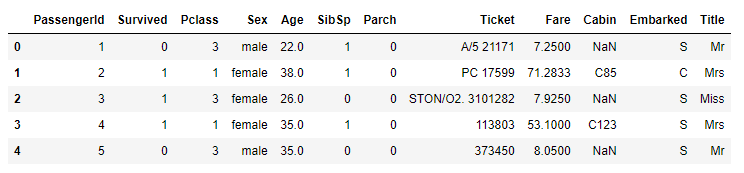
- 마지막으로
Title도 숫자로 변경해 줍니다.
1 2 3 4 5 6 7 | # 변경할 값을 dir로 저장 Title_mapping = {'Mr':0, 'Mrs':1, 'Miss':2, 'Master':3, 'Others':4} for data in data_train_test: data['Title'] = data['Title'].map(Title_mapping).astype(int) train_dt.head() |
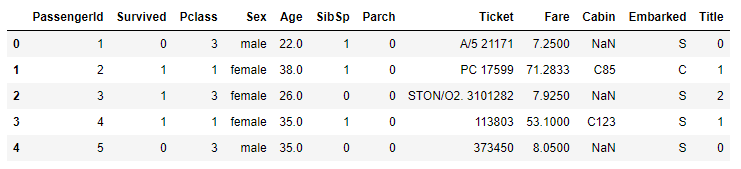
2.2. Pclass
Pclass는 1, 2, 3 클래스로 나누어져 있습니다.- 1 클래스의 생존율이 높고 3클래스는 생존율이 낮습니다.
- 생존유무를 파악하는데 유의미한 지표입니다.
- 기존 데이터가 1, 2, 3 으로 제공되니 그대로 사용하도록 합니다.
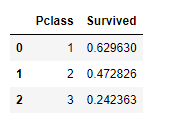
2.3. Sex
Sex는 male(남성), female(여성)으로 나누어져 있습니다.- 남성의 사망률이 높고 여성의 생존율이 높습니다.
- 생존유무를 파악하는데 유의미한 지표입니다.
- 데이터가 male 와 female 로 제공되므로 0과 1로 변경하도록 합시다.
1 2 3 4 5 | # int type 의 숫자 0과 1로 매핑 for data in data_train_test: data['Sex'] = data['Sex'].map({'male':0, 'female':1}).astype(int) train_dt.head() |
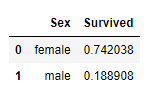
2.4. Age
-
Age에는 결측값이 있기 때문에 이 부분을 먼저 해결해줘야 합니다. -
결측값에
Title별Age의 평균을 넣습니다.
1 2 3 4 5 6 7 8 | # Age 결측값에 Title별 나이의 평균값으로 변경 for data in data_train_test: data['Age'].fillna(data.groupby('Title')['Age'].transform('mean'), inplace=True) # 결측값 확인 train_dt.info() print('-'*6) test_dt.info() |

-
나이는 연속형 자료이므로 구간을 정하면 될 것 같습니다.(ex 10대, 20대…)
-
그냥 단순하게 구간을 나눠도 되지만
좀 있어 보이게Pandas 의 cut 을 사용해 나눠봅시다. -
나누어진 구간의 생존율도 같이 보면 좋을 것 같습니다.
1 2 3 4 5 | # AgeRange에 N등분 한 범위를 넣어줍니다. train_dt['AgeRange'] = pd.cut(train_dt['Age'], 5) # AgeRange 의 값마다 생존율을 구합니다. train_dt[['AgeRange', 'Survived']].groupby(['AgeRange'], as_index=False).mean().sort_values(by='AgeRange', ascending=True) |
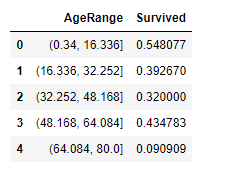
- 5구간으로 나누는게 제일 깜끔한 것 같아서 선택했습니다.
- (0~16) 은 0, (16~32) 는 1,…이렇게 매핑해주도록 합시다.
1 2 3 4 5 6 7 8 9 10 11 | # AgeRange 범위 대로 값 변경 for data in data_train_test: data.loc[ data['Age'] <= 16, 'Age'] = 0 data.loc[(data['Age'] > 16) & (data['Age'] <= 32), 'Age'] = 1 data.loc[(data['Age'] > 32) & (data['Age'] <= 48), 'Age'] = 2 data.loc[(data['Age'] > 48) & (data['Age'] <= 64), 'Age'] = 3 data.loc[ data['Age'] > 64, 'Age'] = 4 # int 로 변경 data['Age'] = data['Age'].astype(int) train_dt.head() |
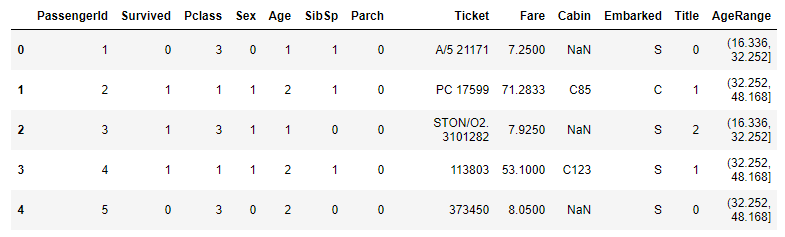
Age도 변환이 잘 됐습니다.- 과정에서 생성된
AgeRange는 삭제해주도록 합시다.
1 2 3 4 | # AgeRange 삭제 train_dt.drop('AgeRange', inplace=True, axis=1) train_dt.head() |
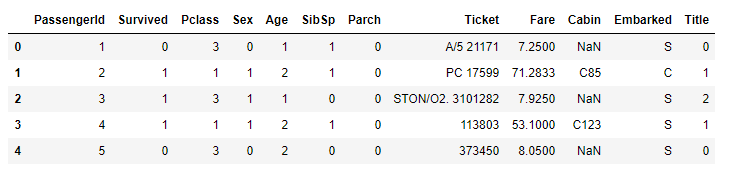
2.4. SibSp + Parch
SibSp는 함께 탑승한 형제자매, 배우자의 총합이고Parch는 함게 탑승한 부모, 자녀의 총합입니다.- 두 Feature를 묶는 이유는 0(혼자인 탑승객) 과 1이상(혼자가 아닌 탑승객) 의 사망률 차이가 의미있기 때문입니다.
SibSp와Parch를 더해주면서 +1을 해주면 한 그룹(가족)의 인원수를 나타낼 수 있습니다.Familysize로 새로운 Feature를 만들어 봅시다.
1 2 3 4 5 | # SibSp + Parch + 1 로 Familysize 생성 for data in data_train_test: data['Familysize'] = data['SibSp'] + data['Parch'] + 1 train_dt.head() |
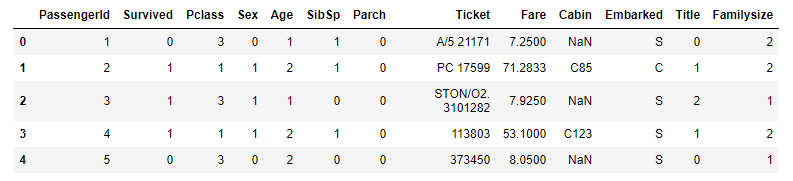
- 만들어진
Familysize로 그래프를 그려서 확인을 해봅니다.
1 2 3 4 5 6 7 8 9 10 11 | %matplotlib inline import matplotlib.pyplot as plt import seaborn as sns #시각화 준비 plt.style.use('seaborn') sns.set(font_scale=2) # 한글 사용 준비 plt.rcParams['font.family']='NanumGothic' |
1 2 3 4 5 6 7 8 9 10 11 | fig, ax = plt.subplots(figsize=(10,6)) # Survived 의 0,1 경우 각각 Faamilysize 의 분포 확인 sns.kdeplot(train_dt[train_dt['Survived'] == 0]['Familysize'], ax=ax) sns.kdeplot(train_dt[train_dt['Survived'] == 1]['Familysize'], ax=ax) # x축의 범위는 0부터 Familysize의 최댓값 ax.set(xlim=(0, train_dt['Familysize'].max())) plt.legend(['사망', '생존']) plt.show() |
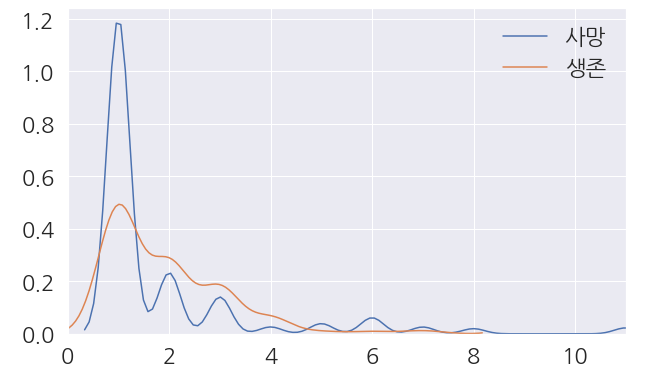
SibSp와Parch는 삭제해 줍니다.
1 2 3 4 5 6 7 | # 삭제할 Feature drop_feature = ['SibSp', 'Parch'] for data in data_train_test: data.drop(drop_feature, inplace=True, axis=1) train_dt.head() |
2.5. Embarked
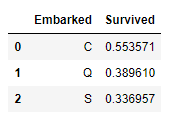
Embarked의 S항구는 Train 데이터의 전체 탑승객 중 72.4% 가 이용한 항구입니다.- 결측값이 Train 데이터에 2개 뿐이므로 S항구로 넣어도 문제없어 보입니다.
1 2 3 4 5 | # Embarked 결측값에 S 삽입 train_dt['Embarked'].fillna('S', inplace=True) # Embarked 결측값 개수 print('결측값의 개수 :',train_dt['Embarked'].isnull().sum()) |
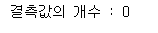
- S, C, Q 의 값도 숫자로 변경합니다.
1 2 3 4 5 6 7 | # 변경할 값을 dir에 저장 embarked_mapping = {'S':0, 'C':1, 'Q':2} for data in data_train_test: data['Embarked'] = data['Embarked'].map(embarked_mapping).astype(int) train_dt.head() |
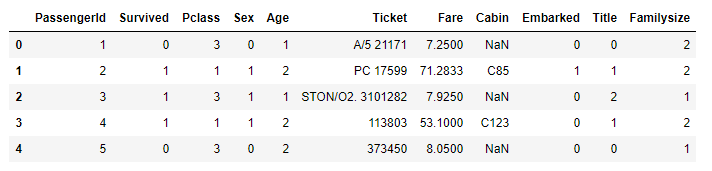
2.6. Fare
Fare도 결측값을 처리해야 합니다.- 가장 연관이 높은
Pclass의 평균으로 결측값을 처리해줍니다.
1 2 3 4 5 6 7 8 | # Fare 결측값에 Pclass별 가격의 평균값으로 변경 for data in data_train_test: data['Fare'].fillna(data.groupby('Pclass')['Fare'].transform('mean'), inplace=True) # 결측값 확인 train_dt.info() print('-'*40) test_dt.info() |

- 결측값을 다 채워줬습니다.
- Pandas 의 cut을 이용해 다시 나눠봅니다.
1 2 3 4 5 | # FareRange에 N등분 한 범위를 넣어줍니다. train_dt['FareRange'] = pd.cut(train_dt['Fare'], 4) # FareRange 의 값마다 생존율을 구합니다. train_dt[['FareRange', 'Survived']].groupby(['FareRange'], as_index=False).mean().sort_values(by='FareRange', ascending=True) |
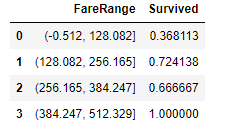
- 다음 범위로 숫자를 다시 지정해 줍니다.
1 2 3 4 5 6 7 8 9 10 | # FareRange 범위 대로 값 변경 for data in data_train_test: data.loc[ data['Fare'] <= 128, 'Fare'] = 0 data.loc[(data['Fare'] > 128) & (data['Fare'] <= 256), 'Fare'] = 1 data.loc[(data['Fare'] > 256) & (data['Fare'] <= 384), 'Fare'] = 2 data.loc[data['Fare'] > 384, 'Fare'] = 3 # int 로 변경 data['Fare'] = data['Fare'].astype(int) train_dt.head() |
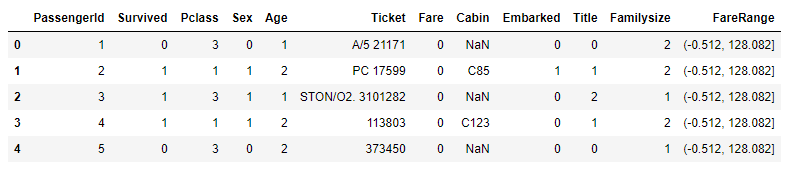
FareRange는 지워줍니다.
1 2 3 4 | # FareRange 제거 train_dt.drop('FareRange', inplace=True, axis=1) train_dt.head() |
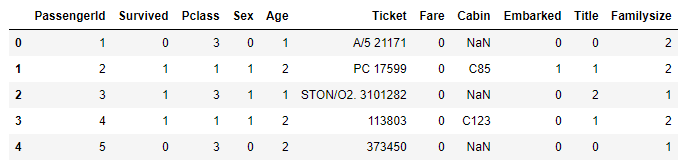
2.7. Ticket + Cabin + PassengerId
Ticket은 결측값이 존재하지 않지만 데이터에서 의미를 찾기가 힘듭니다.Cabin은 결측값이 너무 많아 데이터로 사용하기가 애매합니다.- 이와 같은 이유로 Feature 에서 제외하겠습니다.
1 2 3 4 5 6 7 | # 삭제할 Feature를 List에 저장 data_drop = ['Ticket', 'Cabin', 'PassengerId'] for data in data_train_test: data.drop(data_drop, inplace=True, axis=1) train_dt.head() |
2.8. One-Hot Encoding
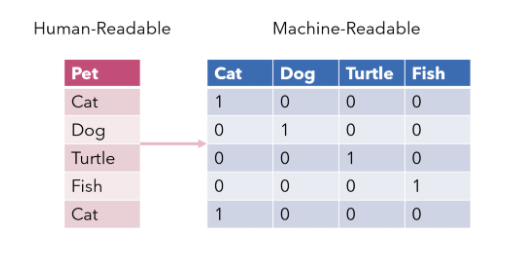
- One-Hot Encoding 이란 단 하나의 값만 True 이고 나머지는 False 로 만드는 인코딩입니다.
- 기계가 좀 더 알아보기 쉽게 해줘 Model의 성능을 향상시키는데 사용됩니다.
- 숫자의 차이가 영향을 미치는 선형 계열 모델에서 범주형 데이터를 처리하기 위해 사용합니다.
- 그림을 보면 조금더 쉽게 이해할 수 있습니다.
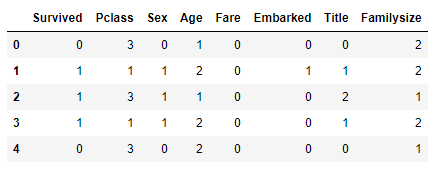
Title에 One-Hot Encoding 을 적용합니다.- Pandas 의 get_dummies 를 이용하면 간단하게 적용할 수 있습니다.
1 2 3 | # Title 에 One-Hot Encoding 진행 train_dt = pd.get_dummies(train_dt, columns=['Title'], prefix='Title') test_dt = pd.get_dummies(test_dt, columns=['Title'], prefix='Title') |
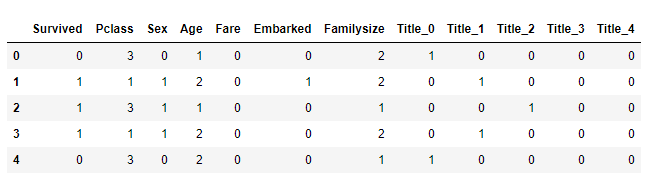
- 최종적으로 만들어진 데이터를 살펴봅시다.
- Train 데이터
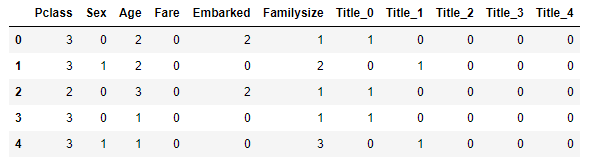
- Test 데이터
- 이번 포스팅은 기계학습을 위한 중요한 작업인 Feature Engineering 을 진행했습니다.
- 다음 포스팅에서는 만든 데이터를 모델에 적용시키고 Kaggle 에 제출하는 과정을 진행합니다.