[Coursera][Muchine Learning] 비지도 학습(Unsupervised Learning)
- 이 포스팅은 Andrew Ng 교수님의 Machine Learning 강의를 정리했습니다.
비지도 학습(Unsupervised Learning, 자율학습)
비지도 학습(Unsupervised Learning) 이란, 출력 값(label)이 주어지지 않거나 아예 없는 데이터를 주고 변수 간의 관계를 기반으로 데이터의 구조(Structure)를 도출 하는 것입니다.
‘정답’이 주어지지 않기 때문에 예측 결과를 기반으로 한 피드백이 없습니다.
군집화 알고리즘(Clustering Algorithm)
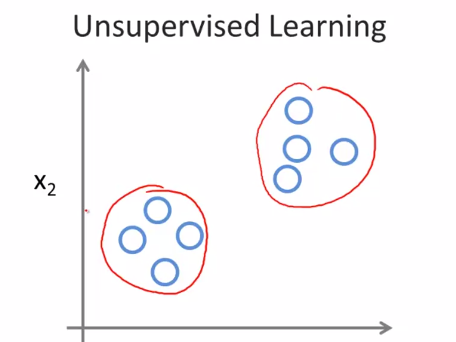
군집화 알고리즘은 다음과 같이 Label 이 주어지지 않은 데이터를 서로 다른 cluster 로 구분지을 수 있습니다.
이 알고리즘은 많은 곳에서 사용되고 있습니다. 예를들면 구글 뉴스가 있습니다.
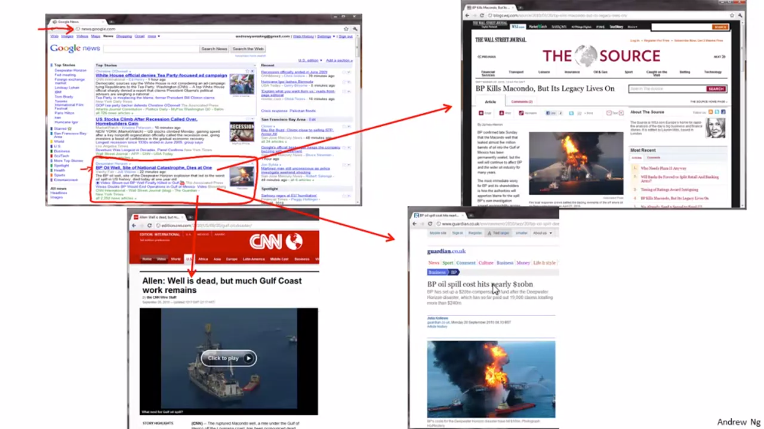
구글 뉴스는 웹에서 매일 수만, 수천 가지의 새로운 기사들을 조사해 연관성이 있는 것 끼리 묶습니다. 그래서 같은 토픽의 모든 기사들을 함께 묶어 표시하는 것입니다.
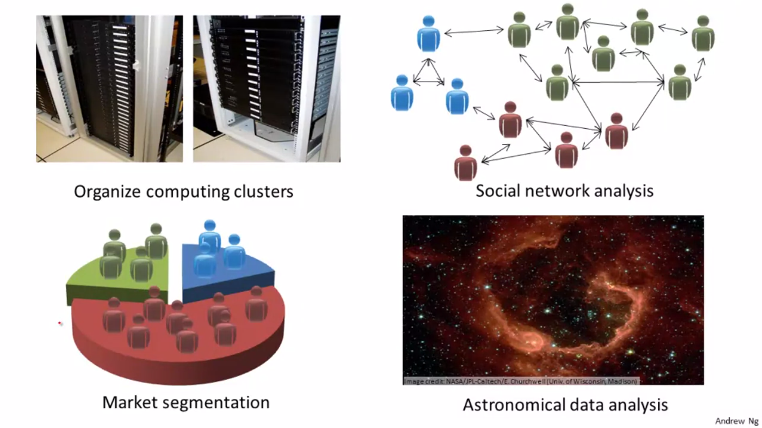
군집화 알고리즘은 유전학적 자료를 이해하는데도 사용됩니다. DNA 로 특정 유전자의 발현 정도를 측정해 사람들을 분류할 수 있습니다. 이외에도 같은 일을 하는 기기들을 분류하는 방법이나 자주 연락하는 친구, 페이스북 친구 분류 등에 사용되는 소셜 네트워크 분석, 고객 정보를 통한 시장의 세분화, 천문학 데이터 문석 등 다양한 곳에서 사용되고 있습니다.
비군집화 알고리즘(Non-Clurstering Algorithm)
칵테일 파티 문제(Cocktail party prolem) 가 있습니다.
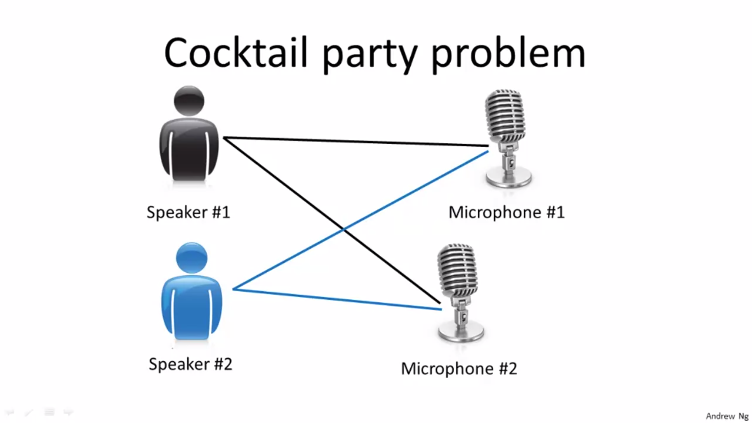
칵테일 파티에서 두 사람이 동시에 이야기를 하고 있을 수 있습니다. 그리고 마이크 2개를 사람으로 부터 서로 다른 거리에 배치합니다. 그렇게 되면 각 마이크는 두 사람의 목소리를 서로 다른 조합으로 녹음하게 됩니다. 가령 1번 화자는 1번마이크에서 좀 더 소리가 클 수도 있고 2번 화자는 2번 마이크에서 좀 더 소리가 클 수 있습니다.
비군집화 알고리즘은 음성이 합쳐진 녹음 결과를 각각의 화자 목소리의 음성 소스로 분리할 수 있습니다. 여기서는 칵테일 파티 알고리즘(Cocktail praty problem algorithm) 이 있습니다.
이 칵테일 파티 알고리즘은 굉장히 복잡할 것이라고 생각할 수 있습니다. 하지만 이는 단 한줄의 코드로 나타낼 수 있습니다.

이는 무료로 공개된 소프트웨어인 Octave 에 내장되어 있는 SVD(Singular value decomposition, 특이값 분해) 함수를 사용했습니다.