[Coursera][Muchine Learning] 지도 학습(Supervised Learning)
- 이 포스팅은 Andrew Ng 교수님의 Machine Learning 강의를 정리했습니다.
지도 학습(Supervised Learning)
지도 학습(Supervised Learning) 이란, ‘출력(정답)’ 이 포함된 데이터의 집합을 알고리즘에게 주어 입력과 출력 사이에 관계를 유추하고 기존의 정보를 이용해 새로운 ‘입력’에 대한 ‘출력’을 예측하는 것입니다.
지도 학습은 회귀(Regression) 와 분류(Classification) 로 나눌수 있습니다.
-
회귀(Regression)
회귀란 연속적인 특징을 가진 값을 예측하는 것입니다.
예를들어 주택의 크기와 가격이 주어진 데이터를 이용해 어떤 주택의 크기가 주어졌을때 가격을 예측하는 것입니다.
다음 그래프로 예시를 확인해 봅시다.
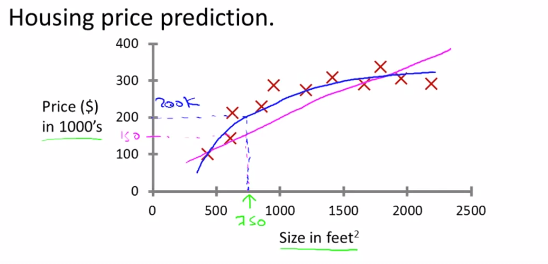
x축 : 주택의 크기(제곱피트)
y축 : 주택의 가격(천 달러)
로 주어졌습니다.
이 상황에서 750 제곱피트짜리 주택을 판매하려면 얼마에 팔 수 있을지 예측하는 것입니다. 지도 학습 알고리즘은 이와 같은 문제를 다양한 방법(직선, 곡선..등)을 사용해 예측에 활용합니다.
-
분류(Classification)
분류란, 0 또는 1, 악성 또는 양성과 같이 불연속적인 결과값을 예측하는 것입니다.
다음 그래프로 예시를 확인해 봅시다.
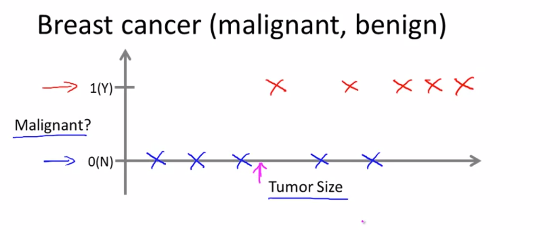
x축 : 종양의 크기
y축 : 해로운지 아닌지 ( yes or no)
즉, 종양이 악성이면 1, 양성이면 0 입니다. 이러한 정보를 가지고 어떤 사람의 종양의 크기로 악성일 가능성을 머신러닝을 통해 예상하는 것 입니다.
다른 특성이 주어질 수도 있습니다.
다음 그래프는 종양의 크기와 환자의 나이가 주어졌을 경우 입니다.
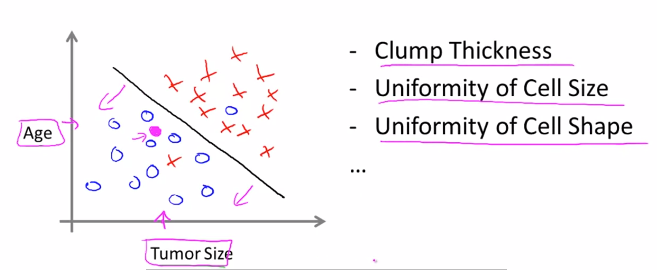
x축 : 종양의 크기
y축 : 환자의 나이
o(양성), x(악성)
다음과 같이 종양의 크기와 나이가 주어졌을 때, 종양이 양성쪽에 있기 때문에 학습 알고리즘은 양성일 가능성이 높다고 판단 할 것입니다.
이 외에도 분류 문제는 결과가 이산적이라면 두개보다 많을 수 있습니다. (ex) 1type, 2type, 3type …
특성도 한개 이상에서 무한한 개수로 주어지기도 합니다.
하지만 무한한 특성을 이용하게 되면 너무 많은 컴퓨터의 메모리 용량을 차지하게 될 수 있습니다.
추후에 학습할 서포트 벡터 머신(Support Vector Machine) 알고리즘에서 무한한 개수의 특성을 다루는 방법을 배울 수 있습니다.