[Kaggle] 자전거 수요 예측(Bike Sharing Demand) (1)EDA
이번에 다뤄볼 주제는 Kaggle 에 있는 Bike Sharing Demand(자전거 수요 예측) 입니다. 여기에 가면 자세한 내용을 볼 수 있습니다.

목표
2년 기간의 시간별 자전거 대여량이 주어집니다. 매월 1일 ~19일의 자전거 대여량과 다른 정보를 바탕으로 매월 20일부터 말일까지의 자전거 대여량을 예측합니다.
1. 탐색적 데이터 분석(EDA)
1.1. 데이터 확보
- 본 포스팅에서 사용한 데이터는 Kagge 에서 받을 수 있습니다.
- 매월 1일 ~19일의 자전거 대여량, 날짜, 기상정보를 가지고 있는 Train 데이터와 매월 20일 ~ 말일까지의 정보를 가지고 있는 Test 데이터가 주어집니다.
1.2. Data Dictionary
-
datetime - hourly date + timestamp (날짜와 시간)
-
season - 1 = spring, 2 = summer, 3 = fall, 4 = winter (계절)
-
holiday - whether the day is considered a holiday (휴일)
-
workingday - whether the day is neither a weekend nor holiday (평일)
-
weather - 1: Clear, Few clouds, Partly cloudy, Partly cloudy (맑은 날씨)
2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist (안개)
3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds (가벼운 눈, 비)
4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog (폭설, 폭우)
-
temp - temperature in Celsius (온도)
-
atemp - “feels like” temperature in Celsius (체감 온도)
-
humidity - relative humidity (상대 습도)
-
windspeed - wind speed (풍속)
-
casual - number of non-registered user rentals initiated (비회원 대여량)
-
registered - number of registered user rentals initiated (회원 대여량)
-
count - number of total rentals (총 대여량)
1.3. 데이터 확인
- 분석에 사용할 라이브러리를 불러옵니다.
1 2 3 4 5 6 7 8 9 | %matplotlib inline import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns plt.style.use('seaborn') sns.set(font_scale=2.5) |
- 데이터를 불러옵니다.
1 2 3 | train_data = pd.read_csv('train.csv') train_data.head() |
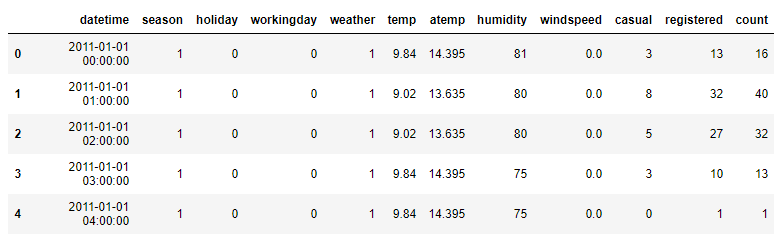
- 데이터가 온전한지 확인합니다.
1 | train_data.info() |
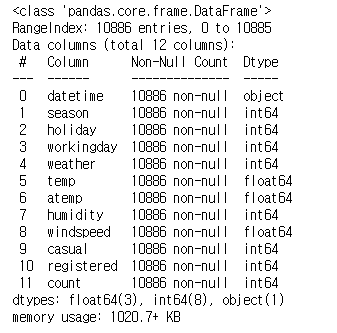
- 결측값은 없어보입니다.
- Test 데이터도 확인해 봅니다.
1 2 3 | test_data = pd.read_csv('test.csv') test_data.head() |
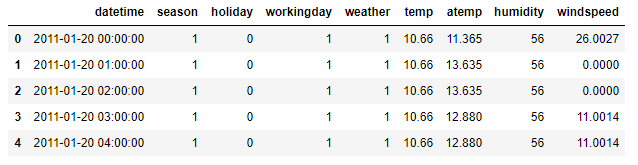
- Test 데이터에는
casual과registered가 없는 것을 확인했습니다. - Train 데이터에만 존재하기 때문에 사용하지 못합니다.
1.3.1. 시각화를 위한 데이터 준비
datetime은 날짜와 시간을 나타내는 정보이므로 Dtype을 datetime 으로 변경합니다.
1 2 | # datetime 열을 datetime 속성으로 변경 train_data['datetime'] = pd.to_datetime(train_data['datetime']) |
- 세부 날짜별 정보를 보기 위해 날짜 데이터를 년도, 월, 일, 시간으로 나눠줍니다.
- 분(minute)과 초(second) 는 모든 값이 0이므로 추가하지 않습니다.
1 2 3 4 5 6 7 | # datetime 에서 year, month, day, hour 추출해서 새로운 Feature만들기 train_data['year'] = train_data['datetime'].dt.year train_data['month'] = train_data['datetime'].dt.month train_data['day'] = train_data['datetime'].dt.day train_data['hour'] = train_data['datetime'].dt.hour train_data.head() |

- 날짜와 시간 데이터는 이정도면 준비된거 같습니다.
- 계절을 나타내는
season과 날씨를 나타내는weather는 그대로 사용합니다.
1.3.2. 시각화(Visualization)
기상 정보인 temp, atemp, humidity, windspeed 의 분포를 히스토그램으로 확인해 봅니다.
1 2 3 4 5 6 | fig, ax = plt.subplots(figsize=(16,12)) # temp, atemp, humidity, windspeed 의 히스토그램 train_data[['temp', 'atemp', 'humidity', 'windspeed']].hist(bins=50, ax=ax) plt.show() |
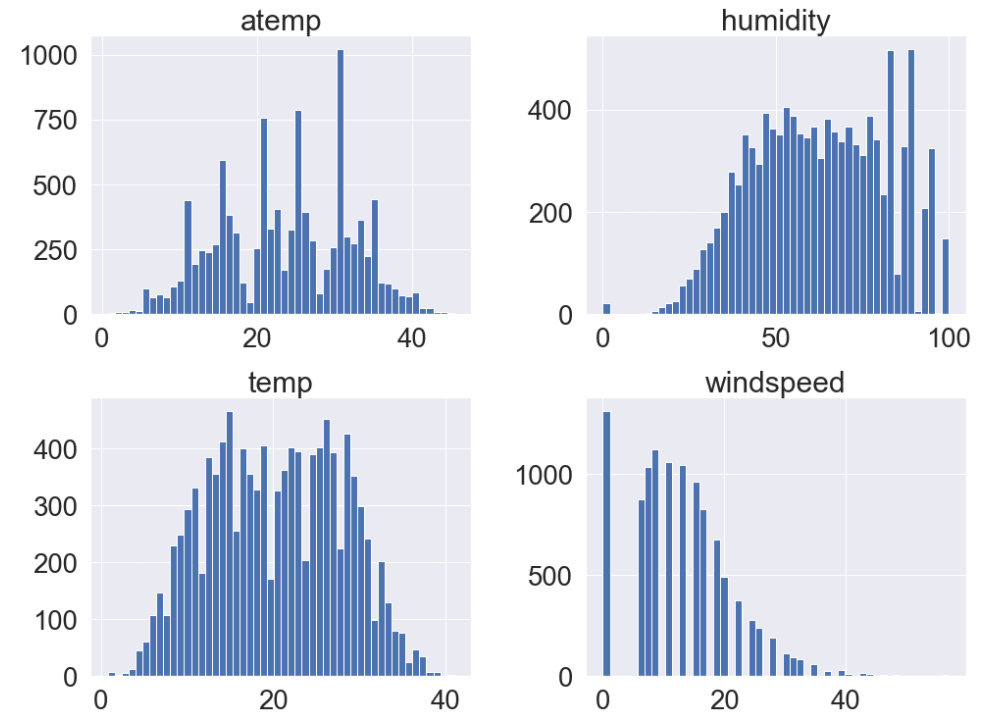
- 분포를 보니 특이한 점으로는
windspeed(풍속)이 0인 데이터가 많이 들어가 있는 게 보입니다.
각 기상정보에 대한 대여량의 산점도를 한번 확인해 봅니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | fig, ax = plt.subplots(2, 2, figsize=(16,14)) # scatter plot ax[0][0].scatter(train_data['atemp'], train_data['count']) ax[0][1].scatter(train_data['humidity'], train_data['count']) ax[1][0].scatter(train_data['temp'], train_data['count']) ax[1][1].scatter(train_data['windspeed'], train_data['count']) # title 지정 ax[0][0].set(title='atemp') ax[0][1].set(title='humidity') ax[1][0].set(title='temp') ax[1][1].set(title='windspeed') plt.show() |
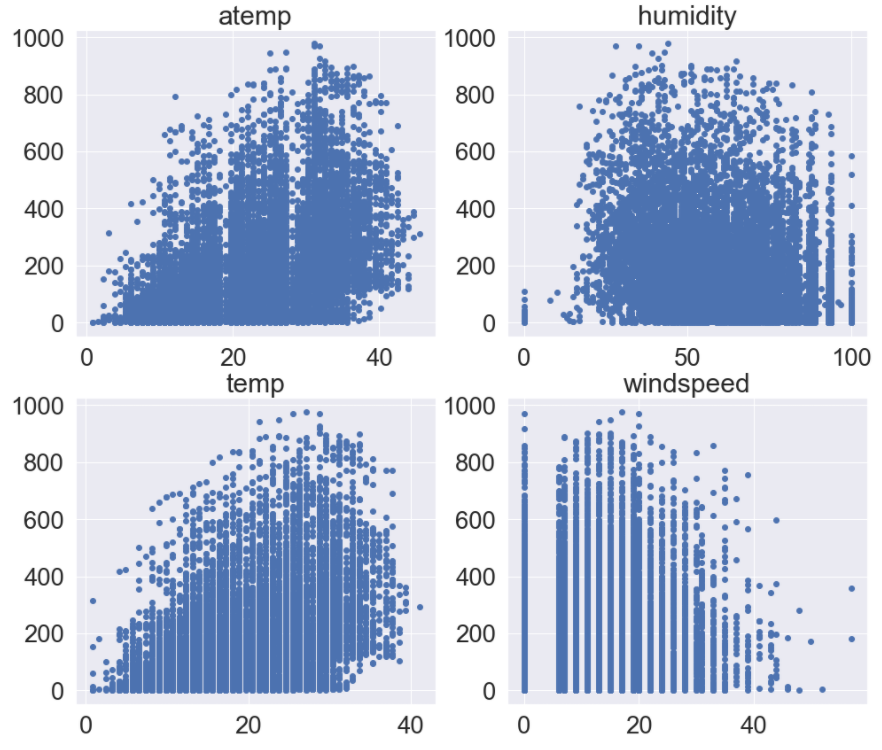
humidity도 많지는 않지만 0과 100에 데이터가 있는게 보입니다.windspeed에는 이상하게 0에 많은 데이터가 몰려 있는 것을 볼 수 있습니다.- 풍속이 0이라는 것은 ‘바람이 불지않고 잔잔하다’ 또는 ‘데이터가 비어있다’ 라고 해석할 수 있을 것 같습니다.
- 온도를 나타내는
temp와 체감 온도를 나타내는atemp는 count 과의 관계가 유사해 보입니다.
다음으론 휴일과 출근을 구분하는 Feature 인 holiday 와 workingday 의 boxplot을 그려봅니다.
1 2 3 4 5 6 7 | fig, ax = plt.subplots(1, 2, figsize=(15,7)) # holiday 와 workingday 의 boxplot sns.boxplot(data=train_data, x='holiday', y='count', ax=ax[0]) sns.boxplot(data=train_data, x='workingday', y='count', ax=ax[1]) plt.show() |
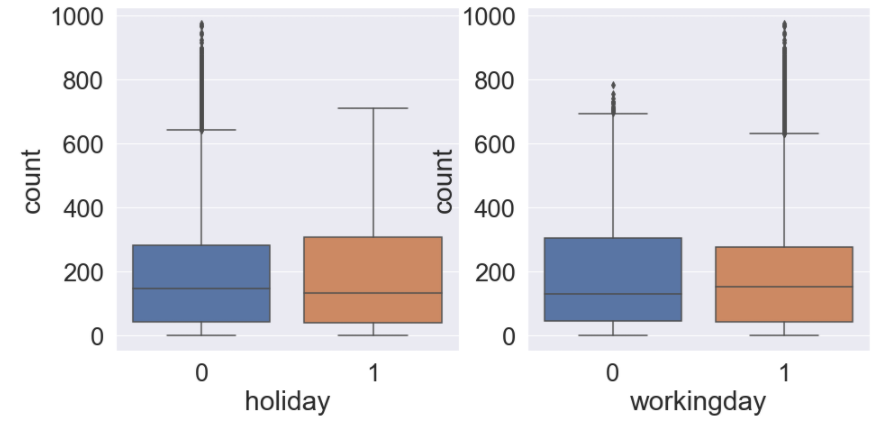
- boxplot을 보면 휴일과 출근에 대한 자전거 대여량은 큰 차이가 없는 것으로 보입니다.
계절과 날씨를 나타내는 season 과 weather 도 boxplot을 확인해 봅니다.
날씨명은 간단하게 1:Sunny / 2:Cloud / 3:Light / 4:Heavy 로 변경해서 확인합니다.
1 2 3 4 5 6 7 8 9 10 11 | fig, ax = plt.subplots(1, 2, figsize=(15,7)) # season 와 weather 의 boxplot sns.boxplot(data=train_data, x='season', y='count', ax=ax[0]) sns.boxplot(data=train_data, x='weather', y='count', ax=ax[1]) #x축 이름 변경 ax[0].set(xticklabels=['Spring', 'Summer', 'Fall', 'Winter']) ax[1].set(xticklabels=['Sunny', 'Cloud', 'Light', 'Heavy']) plt.show() |
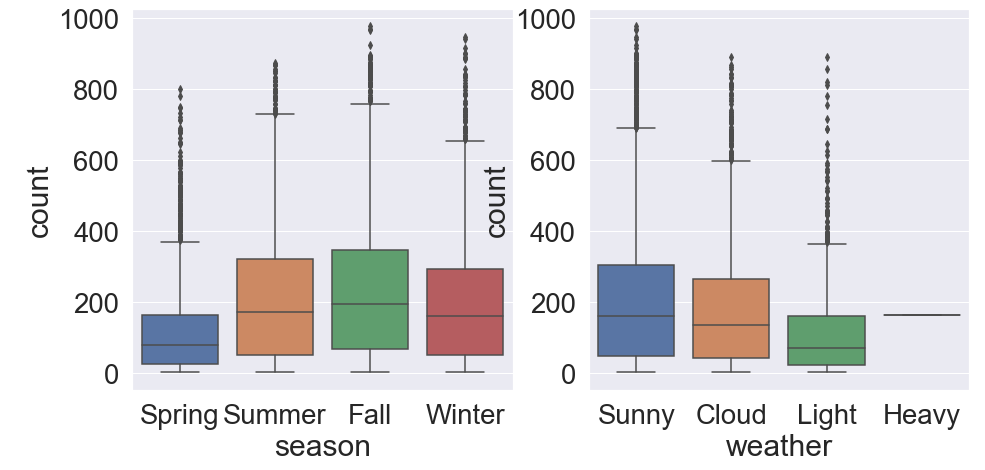
season과weather모두 자전거 대여량에 유의미한 영향을 주는 것 같습니다.- 특히, 심한 눈비가 오는 날씨에는 대여량이 거의 없는 것을 확인할 수 있습니다.
- boxplot을 살펴본 결과 위쪽으로 크게 벗어난 값이 다수 존재하기 때문에 너무 벗어난 값은 처리해줘야 할 것 같습니다.
이제 날짜와 시간을 사용한 시각화를 진행해봅니다.
- 일별 대여량 그래프를 확인합니다.
1 2 3 4 5 6 | fig, ax = plt.subplots(figsize=(15,6)) # 일별 대여량 sns.barplot(data=train_data, x='day', y='count', ax=ax, ci=None) plt.show() |
-
일별 그래프에서는 특별한 점을 찾지 못했습니다.
-
월별 대여량 그래프를 확인합니다.
1 2 3 4 5 6 7 8 9 10 | fig, ax = plt.subplots(figsize=(15,6)) # 월별 대여량 sns.barplot(data=train_data, x='month', y='count', ax=ax, ci=None) # x축 값이름 변경 labels=['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct','Nov', 'Dec'] ax.set(xticklabels=labels) plt.show() |
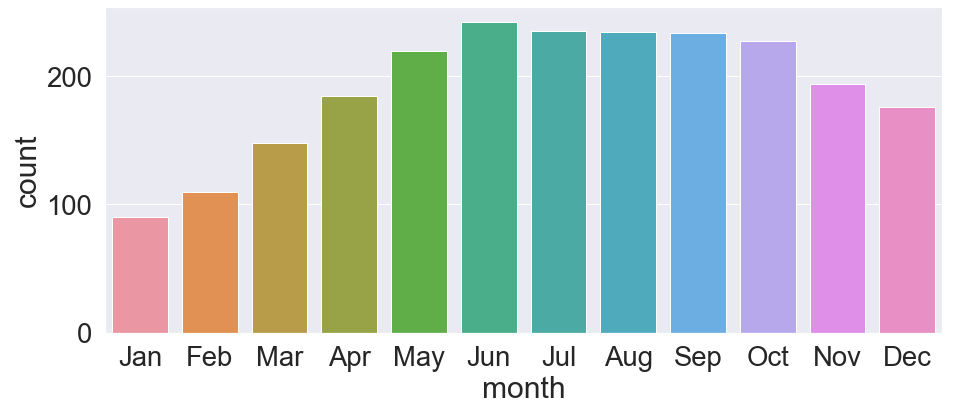
다른 월에 비해 1, 2, 3월이 대여량이 적은 편입니다.
- 계절에 따른 시간별 대여량을 확인해 봅니다.
1 2 3 4 5 6 7 8 9 10 | fig, ax = plt.subplots(figsize=(15,6)) # 계절에 따른 시간별 대여량 sns.pointplot(data=train_data, x='hour', y='count',hue='season', ax=ax, ci=None) # x축 값이름 변경 labels=['Spring', 'Summer', 'Fall', 'Winter'] ax.legend(labels=labels) plt.show() |
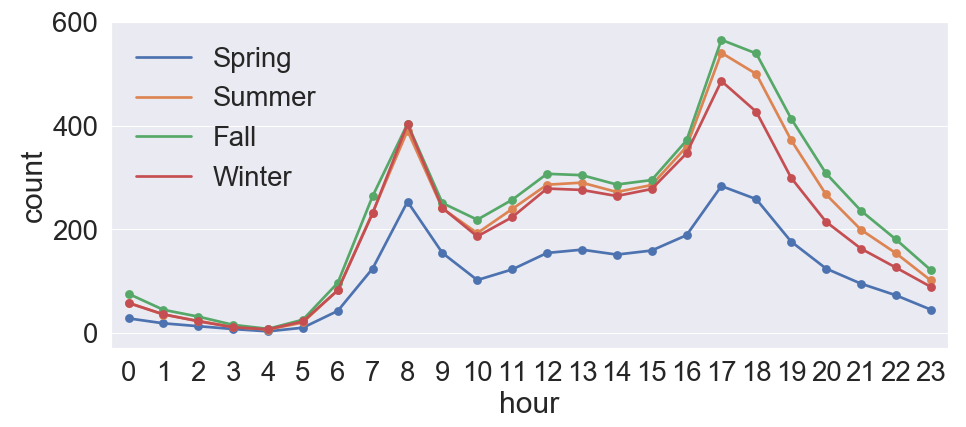
- 출퇴근 시간으로 예상되는 8시, 17시, 18시에 대여량이 가장 높습니다.
- 봄(Spring)의 대여량이 다른 계절에 비해 상대적으로 낮게 나옵니다.
봄보다 겨울 대여량이 많은 것이 신기해 계절을 어떻게 나눴는지 확인해 봅니다.
1 2 | # 계절과 월의 교차표 pd.crosstab(train_data['season'], train_data['month']) |
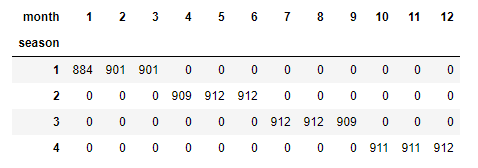
- 1, 2, 3월 봄
- 4, 5, 6월 여름
- 7, 8, 9월 가을
- 10, 11, 12월 겨울
로 나뉘어 있는 것을 볼 수 있습니다.
데이터를 다시 살펴보니 워싱턴DC 지역이라고 나와있어서 원별 온도를 찾아봤습니다.
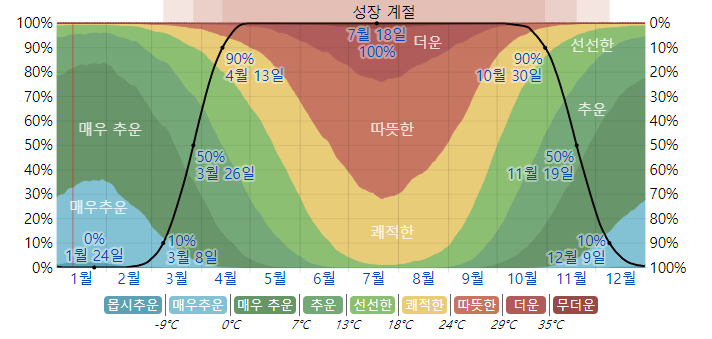
출처 : https://ko.weatherspark.com/y/20957/%EB%AF%B8%EA%B5%AD-%EC%BB%AC%EB%9F%BC%EB%B9%84%EC%95%84-%ED%8A%B9%EB%B3%84%EA%B5%AC-%EC%9B%8C%EC%8B%B1%ED%84%B4-D.C.%EC%9D%98-%EB%85%84%EC%A4%91-%ED%8F%89%EA%B7%A0-%EB%82%A0%EC%94%A8
- 그래프를 보니 1, 2, 3월을 나타내는 봄이 왜 대여량이 낮은지 알 것 같습니다.
날씨에 따른 시간별 대여량을 알아봅니다.
1 2 3 4 5 6 7 8 9 10 | fig, ax = plt.subplots(figsize=(15,6)) # 날씨에 따른 시간별 대여량 sns.pointplot(data=train_data, x='hour', y='count',hue='weather', ax=ax, ci=None) # x축 값이름 변경 labels=['Sunny', 'Cloud', 'Light', 'heavy'] ax.legend(labels=labels) plt.show() |
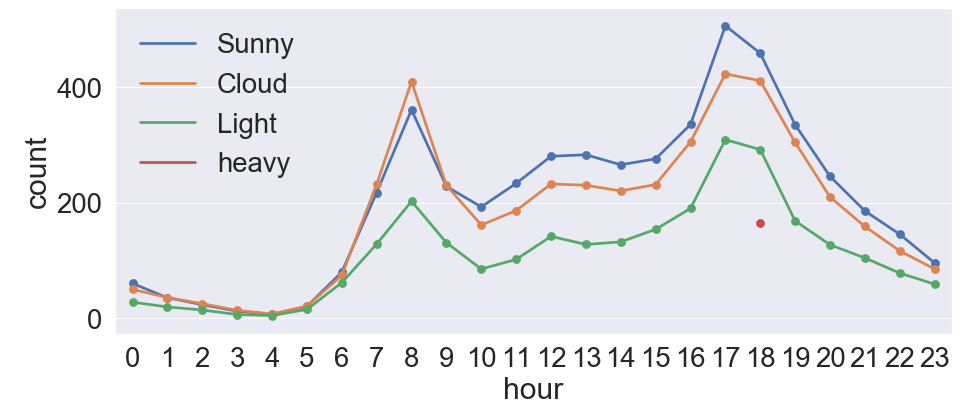
- 어느정도 예측 가능한 그래프가 나왔습니다.
- 출퇴근 시간이라고 예상되는 8시, 17시, 18시가 가장 대여량이 많습니다.
- 폭우와 폭설이 내리는 날씨(heavy)는 대여량이 거의 없는 것을 볼 수 있습니다.
요일에 따른 시간별 대여량에도 차이가 있는지 확인해 봅니다.
1 2 3 4 5 6 7 8 9 | # 요일이름 Feature 만들기 train_data['day_name'] = train_data['datetime'].dt.day_name() fig, ax = plt.subplots(figsize=(20,8)) # 요일에 따른 시간별 대여량 sns.pointplot(data=train_data, x='hour', y='count',hue='day_name', ax=ax, ci=None) plt.show() |
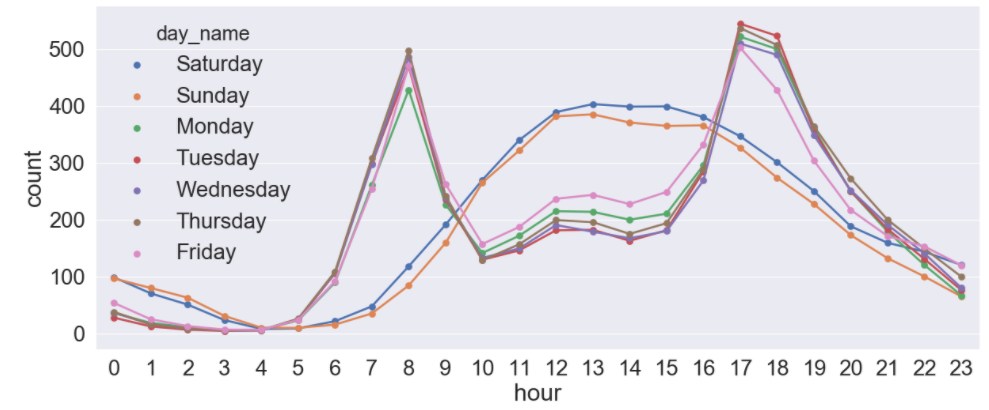
- 앞서 살펴본 boxplot 에서는 주말과 평일의 총 대여량 차이를 알 수 없었지만 시간별 대여량을 보니 주말과 평일의 차이가 확연하게 보입니다.
EDA를 진행하면서 데이터의 분포를 확인했고 Feature 들을 이용해 시각화를 하며 데이터 간 특징을 찾아내는 과정을 진행했습니다. 다음 포스팅에서는 찾아낸 특징들을 바탕으로 Feature Engineering을 하며 전처리 과정을 진행하겠습니다.