[Kaggle] 자전거 수요 예측(Bike Sharing Demand) (2)Feature Engineering
2. Feature Engineering
- 시작하기 전에 사용할 수 있을 만한 Feature 들을 추려서 상관관계 지수를 heatmap으로 확인해 봅니다.
1 2 3 4 5 6 7 8 9 | # 상관관계에 사용할 Feature 지정 corr_train = train_data[['count', 'season', 'holiday', 'workingday', 'weather', 'temp', 'atemp', 'humidity', 'windspeed', 'month', 'day', 'hour']].corr() fig, ax = plt.subplots(figsize=(20,12)) # heatmap sns.heatmap(data=corr_train, ax=ax, linewidths=0.1, linecolor='white', annot=True, cmap=plt.cm.RdBu) plt.show() |
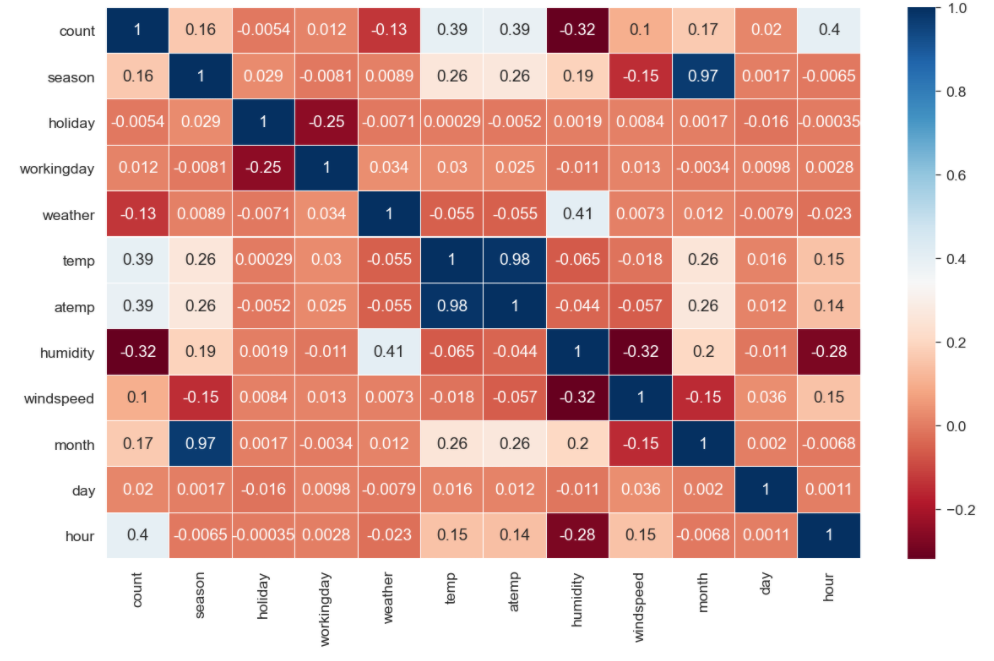
- 특이한 점으로는
month와season그리고temp와atemp의 상관 관계가 매우 높게 나왔습니다. - 특히
temp와atemp의 경우에는 거의 같은 Feature 라고 생각해도 될 것 같습니다. - 이제 학습에 사용할 Feature를 선별해봅시다.
- 간단한 것 먼저 처리합니다.
2.1. 날짜, 시간 관련
- 날짜와 시간에 관련된 Feature 는
datetime,holiday,workingday,year,month,day,hour,day_name이 있습니다. - 숫자형으로 나타나는
holiday,workingday,month,hour를 사용하고 나머지는 제거해 줍니다. - 주말과 평일의 차이가 있지만 이를 나타내는 Feature가 있으므로 사용하지 않습니다. (
holiday,workingday)
1 2 3 4 5 6 7 8 | # datetime, day, day_name, year 제거 train_data.drop(['datetime', 'day', 'day_name', 'year'], inplace=True, axis=1) # month, hour 은 범주형으로 변경 train_data['month'] = train_data['month'].astype('category') train_data['hour'] = train_data['hour'].astype('category') train_data.head() |
2.2. season, weather
season과weather은 범주형 Feature 입니다.- 두 Feature 모두 숫자로 표현돼 있으니 One-Hot Encoding을 진행해 줍니다.
1 2 3 4 | # One-hot encoding 진행 train_data = pd.get_dummies(train_data, columns=['season','weather']) train_data.head() |

2.3. casual, registered
casual,registered는 test 데이터에서는 존재하지 않기 때문에 과감하게 삭제해 줍니다.
1 2 3 4 | # casual, registered 제거 train_data.drop(['casual', 'registered'], inplace=True, axis=1) train_data.head() |

2.4. temp, atemp, humidity, windspeed
-
temp와atemp는 상관관계가 매우 높고 두 Feature 의 의미가 비슷하기 때문에temp만 사용하기로 합니다. -
windspeed는 0값이 많은 특징이 있습니다. -
0이 측정을 하지 못한 결측값일 수 있지만 NaN과 같이 표시가 돼있지 않습니다.
-
바람이 불지않는 잔잔한 상태를 0으로 나타내는 경우도 있다고 합니다.
-
그렇기 때문에 우선은 0값 그대로 진행합니다.
-
atemp만 지워줍니다.
1 2 3 4 | # atemp 제거 train_data.drop('atemp', inplace=True, axis=1) train_data.head() |

2.5. test 데이터
- train 데이터에 적용한 내용을 test 데이터에도 적용해 줍니다.
train 데이터 할때 같이 하는게 편함
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # datetime 타입으로 변경 test_data['datetime'] = pd.to_datetime(test_data['datetime']) # month와 hour 추출 test_data['month'] = test_data['datetime'].dt.month test_data['hour'] = test_data['datetime'].dt.hour # month와 hour 범주화 타입으로 변경 test_data['month'] = test_data['month'].astype('category') test_data['hour'] = test_data['hour'].astype('category') # One-hot encoding test_data = pd.get_dummies(test_data, columns=['season','weather']) # 사용하지 않는 feature 삭제 drop_feature = ['datetime', 'atemp'] test_data.drop(drop_feature, inplace=True, axis=1) test_data.head() |

학습 준비 완료!
솔직히 이번 포스팅을 하면서 다양한 뻘짓(?)들을 해보느라 오래 걸렸습니다.
모든 내용을 추가하기에는 내용이 너무 복잡해지고 방향성을 잃을거 같아서 베이직하게 진행했습니다. 다양한 뻘짓은 추후에 개선작업을 할 때 포스팅 해보도록 하겠습니다.
다음편은 모델링 입니다.