[Kaggle] Titanic 생존자 예측 (3) Modeling
이전 포스팅에서 기계학습을 위한 Feature Engineering을 진행해 학습에 사용할 Train 데이터와 테스트에 사용할 Test 데이터를 만들고 One-Hot Encoding을 진행했습니다. 이번 포스팅에서는 Model에 학습시키고 예측하는 과정을 진행하겠습니다.
3. Modeling
- 우선 이 프로젝트는 Train 데이터로 정답을 알려주며 학습시키는 지도학습입니다.
- 지도학습은 크게 분류(Classification) 과 회귀(Regression) 가 있습니다.
- Titanic 생존 예측은 0(사망)/1(생존) 두 가지 중 하나로 분류하는 이진 분류(Binary Classification) 에 속합니다.
- 머신러닝에 사용되는 알고리즘을 제공하는 Python 라이브러리 Scikit-Learn을 사용합니다.
3.1. Train-Validation-Test
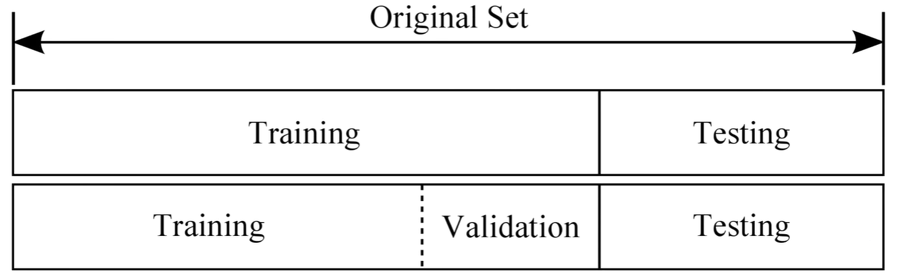
- 가지고 있는 Train 데이터를 Train set과 Validation set으로 나눠야 합니다.
- Train set 으로 학습한 후 Validation set 을 이용해 모델의 성능을 평가해야 합니다.
- Test 데이터는 모델의 최종 성능을 평가하기 위해 사용되기 때문입니다.
- 데이터를 분리하기 위한 사전작업을 해줍니다.
- Sklearn의 train_test_split을 불러옵니다.
1 2 | # 데이터 분리 준비 from sklearn.model_selection import train_test_split |
- 7:3의 비율로 Train set 과 Validation set 을 생성합니다.
1 2 3 4 5 6 7 | # Train, Test, Target을 분리 X_train = train_dt.drop('Survived', axis=1).values target_label = train_dt['Survived'].values X_test = test_dt.values # train_test_split 을 사용해 7:3의 비율로 train set과 validation set을 생성 X_tr, X_vid, y_tr, y_vid = train_test_split(X_train, target_label, test_size=0.3, random_state=1230, shuffle=True) |
3.2. Model
- 사용할 모델
- Logistic Regression
- K-Nearest Neighbors(K-NN)
- Decision Tree
- Random Forest
- Naive Bayes
- Support Vector Machine(SVM)
- Model 을 하나하나 분석하기 보다는 사용위주의 측면에서 진행합니다.
- 이번 분석에서는 Parameter 은 대부분 Default 값을 사용합니다.
- 사용할 Model 을 가져옵니다.
1 2 3 4 5 6 7 8 9 10 | # 분석 모델 가져오기 from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC # 분석 성능을 측정할 도구 from sklearn import metrics |
3.2.1. Logistic Regression
-
Logistic Regression(로지스틱 회귀) 는 데이터가 어떤 범주에 속할 확률을 0에서 1사이의 값으로 예측하고 분류하는 알고리즘입니다.
-
Model을 사용하는 방법은 간단합니다.
-
X_tr 과 y_tr 을 학습한 후 X_vid를 이용해 예측합니다.
1 2 3 4 5 6 7 8 | # Model 적용 model = LogisticRegression() model.fit(X_tr, y_tr) #예측 prediction = model.predict(X_vid) prediction |

- 다음과 같이 사망과 생존을 예측했습니다.
- 예측한 결과의 정확도(Accuracy)를 측정합니다.
1 2 | #예측값으로 accuracy 측정 print('Logistic Regression - {:.2f}% 확률로 생존 맞춤'.format(metrics.accuracy_score(prediction, y_vid) * 100)) |
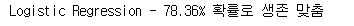
- 78.36%의 정확도로 생존율을 맞췄습니다.
- 같은 방법으로 다른 Model 도 측정해 봅니다.
3.2.2. K-Nearest Neighbors(K-NN)
- K-NN(최근접 이웃)은 가장 가까운 거리에 있는 K개의 이웃과 비교하여 예측하는 방법입니다.
- K의 값는 Default 값으로 5를 가집니다.
1 2 3 4 5 6 7 8 9 | # Model 적용 model = KNeighborsClassifier() model.fit(X_tr, y_tr) #예측 prediction1 = model.predict(X_vid) #예측값으로 accuracy 측정 print('K-Nearest Neighbors - {:.2f}% 확률로 생존 맞춤'.format(metrics.accuracy_score(prediction1, y_vid) * 100)) |
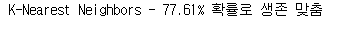
3.2.3. Decision Tree
- Decision Tree(의사결정 나무) 는 규칙들을 나무구조로 도표화해 분류와 예측을 수행하는 방법입니다.
1 2 3 4 5 6 7 8 9 | # Model 적용 model = DecisionTreeClassifier() model.fit(X_tr, y_tr) #예측 prediction2 = model.predict(X_vid) #예측값으로 accuracy 측정 print('Decision Tree - {:.2f}% 확률로 생존 맞춤'.format(metrics.accuracy_score(prediction2, y_vid) * 100)) |
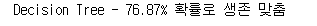
3.2.4. Random Forest
- Random Forest(랜덤 포레스트) 는 Ensemble(앙상블) 기법 중 하나로 무작위로 약한 학습기를 생성한 후 이를 선형결합하여 최종 학습기를 만드는 방법입니다.
1 2 3 4 5 6 7 8 9 | # Model 적용 model = RandomForestClassifier() model.fit(X_tr, y_tr) #예측 prediction3 = model.predict(X_vid) #예측값으로 accuracy 측정 print('Random Forest - {:.2f}% 확률로 생존 맞춤'.format(metrics.accuracy_score(prediction3, y_vid) * 100)) |
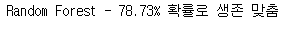
3.2.5. Naive Bayes
- Naive Bayes(나이브 베이즈)는 조건부확률을 계산하는 방법 중 하나인 베이즈 정리에 기반한 분류 방법입니다.
1 2 3 4 5 6 7 8 9 | # Model 적용 model = GaussianNB() model.fit(X_tr, y_tr) #예측 prediction4 = model.predict(X_vid) #예측값으로 accuracy 측정 print('Naive Bayes - {:.2f}% 확률로 생존 맞춤'.format(metrics.accuracy_score(prediction4, y_vid) * 100)) |
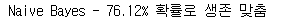
3.2.6. Support Vector Machine(SVM)
- SVM은 분류를 위한 기준 선을 정의해 경계의 어느 쪽에 속하는지 확인해 분류하는 방법입니다.
1 2 3 4 5 6 7 8 9 | # Model 적용 model = SVC() model.fit(X_tr, y_tr) #예측 prediction5 = model.predict(X_vid) #예측값으로 accuracy 측정 print('Support Vector Machine - {:.2f}% 확률로 생존 맞춤'.format(metrics.accuracy_score(prediction5, y_vid) * 100)) |
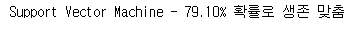
- 6가지의 알고리즘을 사용해 예측을 돌려본 결과
- Logistic Regression-78.36%
- K-Nearest Neighbors(K-NN) - 77.61%
- Decision Tree - 76.87%
- Random Forest - 78.73%
- Naive Bayes - 76.12%
- Support Vector Machine(SVM) - 79.10%
- Support Vector Machine 이 예측 정확도가 가장 높게 나왔습니다.
- 하지만 만들어진 Model은 테스트로 사용한 Validation set 에만 잘 동작하게 됩니다.
- train_test_split으로 다시 Train set과 Validation set을 만든다면 모델의 성능은 계속 달라질 것입니다.
- 이 문제를 해결하기 위해 Cross Validation(교차 검증)을 사용할 수 있습니다.
3.3. Cross Validation
- Cross Validation(교차 검증) 은 Train 데이터의 모든 부분을 사용하여 모델을 검증하는 방법입니다.
- 교차 검증 방법 중 가장 일반적으로 사용되는 K-fold를 사용합니다.
3.3.1. K-fold Cross Validation

-
위의 사진은 K=5의 Fold로 나눴을때 모습입니다.
-
K-fold 는 Train 데이터를 K등분하고 나누어진 데이터를 K개로 다시 나누어 그 안에서 학습과 검증을 K번 반복해 평균을 구하는 검증 방법입니다.
-
Sklearn에서 K-Fold를 가져옵니다.
1 2 3 | # K-Fold를 위한 준비 from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score |
- K-Fold와 Model을 사용할 데이터를 준비합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # K = 10 의 K-Fold 설정 kfold = KFold(n_splits=10, random_state=1230) # Model 의 결과를 담을 List 생성 mean = [] accuracy = [] std = [] # 사용할 Model 명 classifiers = ['Logistic Regression', 'K-Nearest Neighbors(K-NN)', 'Decision Tree', 'Random Forest', 'Naive Bayes', 'Support Vector Machine(SVM)'] # 사용할 Model 설정 models = [LogisticRegression(), KNeighborsClassifier(), DecisionTreeClassifier(), RandomForestClassifier(), GaussianNB(), SVC()] |
- 모델을 한번에 적용해 모델별 acuuracy 평균과 표준편차를 확인해 봅니다.
1 2 3 4 5 6 7 8 9 10 11 | # Model 적용 for i in models: model = i cv_result = cross_val_score(model, X_train, target_label, cv = kfold, scoring='accuracy') cv_result = cv_result mean.append(cv_result.mean()) std.append(cv_result.std()) # Model 별 accuracy 평균과 표준편차 kfold_models_dataframe = pd.DataFrame({'CV mean':mean, 'Std':std}, index=classifiers) kfold_models_dataframe |
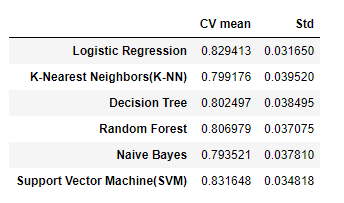
- 위의 표를 보면 평균 정확도(CV mean)는 높지만 표준편차(Std)가 큰 모델들이 있습니다.
- 평균 정확도(CV mean)는 높고 표준편차(Std)는 작은 모델을 선별해보면 약 83% 정확도를 가진 Logistic Regression 을 선택할 수 있습니다.
3.4. Submission
- Logistic Regression을 채택해 test 데이터를 예측합니다.
1 2 3 4 | # Logistic Regression 으로 학습 후 예측 clf = LogisticRegression() clf.fit(X_train, target_label) prediction_LG = clf.predict(test_dt) |
- 예측한 결과로 Submission 파일을 만들어 줍니다.
1 2 3 4 5 6 7 8 | # 제출에 Submission 파일 불러오기 submission = pd.read_csv('gender_submission.csv') # 예측값 업데이트 submission['Survived'] = prediction_LG # CSV 파일로 제작 submission.to_csv('titanic_submission.csv', index=False) |
- 생성한 submission 파일을 Kaggle에 제출해봅니다.
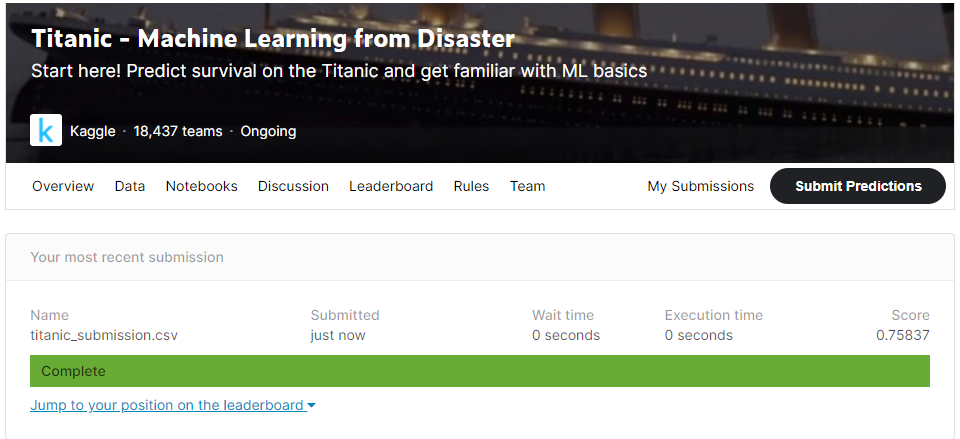
- 위에서 확인한 정확도 보다 떨어진 Score 0.75837 을 받았습니다.
3.5. Thinking
- 예측 Model의 성능을 올리기 위해 개선해야 할 점을 생각해봅니다.
- EDA를 더 자세하게 해보기
- NaN(결측값)을 다른 방법으로 처리하기
- Feature Enginnering을 다양한 방법으로 적용시키기
- Ticket, Cabin 과 같은 사용하지 않은 Feature 활용해보기
- Model 설계 과정에서 parameter 값을 tuning 해보며 최적화 값 찾기
3.6. 마치며
머신러닝을 접하고 Kaggle을 알게되어 처음으로 진행한 주제였습니다. 머신러닝을 처음 접하고 시작해보고 싶을때 좋은 주제라고 생각합니다. 튜토리얼로 많이 사용되지만 Kaggle 에 있는 여러 사람들의 Notebook을 보며 공부하는 것이 정말 도움이 많이 됩니다. 조금씩 수정을 해가며 Model의 성능을 올리는 방법도 공부해야겠다고 느꼈습니다.
이번 포스팅에서 사용한 Model 들은 좀 더 공부와 이해를 하고 각각 포스팅을 해볼 생각입니다. (언제일지는 잘모름)
공부를 하면서 도움을 받은 곳
- Kaggle 에 있는 수많은 인기 Notebook
- 이유한님 Youtube