[시각화]치솟는 부동산과 하락하는 출산율(부동산편)+마무리
이전 포스팅에서는 인구에 대한 데이터를 시각화 해봤습니다. 이번 포스팅에서는 부동산과 관련된 데이터를 시각화 하면서 상관관계가 있는지 알아보겠습니다.
2. 부동산
부동산 가격의 지표 변화를 확인해봅니다.
2.1. 데이터 확보
- 부동산 가격과 관련이 있는 전세, 매매등의 가격 지수 데이터를 확보합니다.
- 한국은행 경제통계시스템 에서 관련 데이터를 원하는 형태로 받을 수 있습니다.
2.2. 데이터 확인 및 시각화
2.2.1. 주택매매가격지수
- 유형별 주택매매 가격지수를 확인해봅니다.
1 2 | df4 = pd.read_csv('주택매매가격지수(2019.01=100).csv', encoding='cp949', skipfooter=9, skiprows=3) df4.head() |
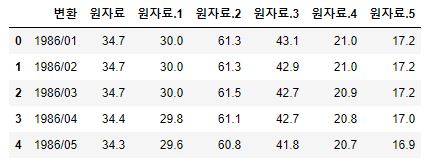
- 데이터의 기간은 1986년 1월부터 2021녀 6월 까지있습니다.
- 지수의 기준은 2019년 1월입니다.
- 컬럼명과 날짜를 변경해줍니다.
1 2 3 4 5 6 7 8 | # Column 명 변경 re_columns=['시점', '총지수', '총지수(서울)', '단독주택', '연립주택', '아파트', '아파트(서울)'] df4.columns=re_columns # 시점을 datetime 으로 변경 df4['시점'] = pd.to_datetime(df4['시점']) df4.head() |
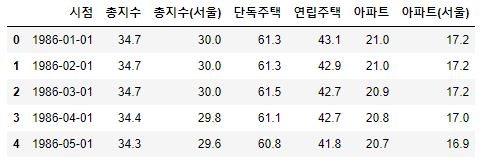
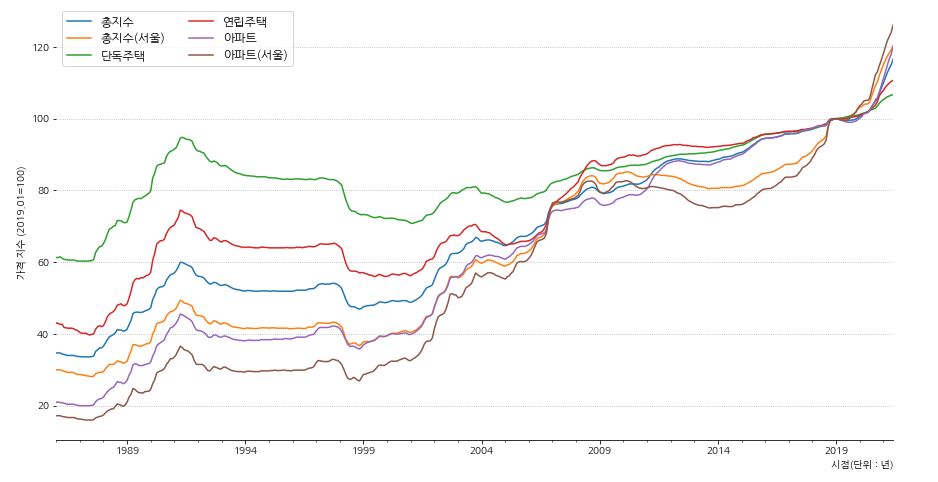
- 시각화를 진행해봅니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | fig, ax = plt.subplots(figsize=(15,8)) df4.plot(x='시점', ax=ax) # 축 제거 ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # x, y축 label 표시 ax.set_xlabel('시점(단위 : 년)',loc='right') ax.set_ylabel('가격 지수 (2019.01=100)') # grid 설정 ax.grid(axis='y', ls=':') # 범례 설정 ax.legend(ncol=2, fontsize=12) plt.show() |
- 가격 지수의 기준점을 그래프에 text로 표기해 줍니다.
- text를 삽입에는 다양한 방법이 존재하지만 annotate를 사용하겠습니다.
- matplotlib의 공식문서에서 parameter들을 자세하게 확인할 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | fig, ax = plt.subplots(figsize=(15,8)) df4.plot(x='시점', ax=ax) # 축 제거 ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # 기준점 표시 ax.annotate('2019.01=100', xy=('2019-01-01', 100.5), xytext=('2017-01-01', 110), arrowprops={'facecolor':'gray', 'arrowstyle':'-|>'}, horizontalalignment='center', fontsize=15, color='black') # x, y축 label 표시 ax.set_xlabel('시점(단위 : 년)',loc='right') ax.set_ylabel('가격 지수 (2019.01=100)') # grid 설정 ax.grid(axis='y', ls=':') # 범례 설정 ax.legend(ncol=2, fontsize=12) plt.show() |
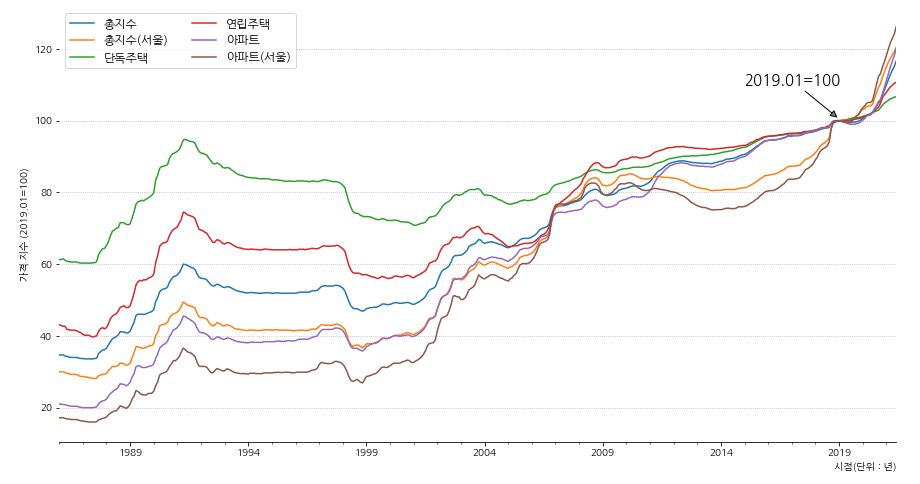
- 전체적으로 가격 지수가 상승중인 것을 파악할 수 있습니다.
- 가장 눈에 띄는 서울 아파트는 가격 지수의 변동폭이 상당히 크고 최근 급격하게 상승중인 것을 알 수 있습니다.
- 모든 가격 지수의 모양이 비슷한 패턴을 보이고 있기 때문에 이 부분은 특정 년도의 정보를 찾아봐야 할 것 같습니다.
2.2.2. 주택전세가격지수
- 주택전세가격지수는 다른 양상을 보이는지 확인해봅니다.
1 2 | df5 = pd.read_csv('주택전세가격지수(2019.01=100).csv', encoding='cp949', skipfooter=9, skiprows=3) df5.head() |
- 지수의 기준은 2019년 1월입니다.
- 컬럼명과 날짜를 변경해줍니다.
1 2 3 4 5 6 7 8 | # Column 명 변경 re_columns=['시점', '총지수', '총지수(서울)', '단독주택', '연립주택', '아파트', '아파트(서울)'] df5.columns = re_columns # 시점을 datetime 으로 변경 df5['시점'] = pd.to_datetime(df5['시점']) df5.head() |
- 마찬가지로 시각화를 진행해 변화를 확인해봅니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | fig, ax = plt.subplots(figsize=(15,8)) df5.plot(x='시점', ax=ax) # 축 제거 ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # 기준점 표시 ax.annotate('2019.01=100', xy=('2019-01-01', 100.5), xytext=('2017-01-01', 110), arrowprops={'facecolor':'gray', 'arrowstyle':'-|>'}, horizontalalignment='center', fontsize=15, color='black') # x, y축 label 표시 ax.set_xlabel('시점(단위 : 년)',loc='right') ax.set_ylabel('가격 지수 (2019.01=100)') # grid 설정 ax.grid(axis='y', ls=':') # 범례 설정 ax.legend(ncol=2, fontsize=12) plt.show() |
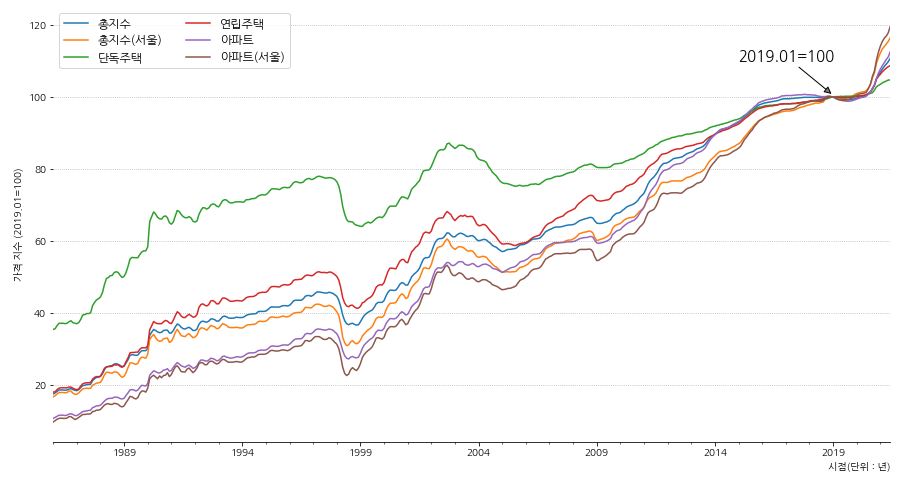
- 전세가격도 전체적으로 꾸준히 상승중인 것을 확인 할 수 있습니다.
- 전세가격 또한 서울과 서울 아파트의 가격 지수가 가파르게 증가하는 것을 볼 수 있습니다.
2.2.3. 지역별 아파트 실거래 가격지수
- 주택매매와 전세 가격지수를 보면 특히나 아파트가 가파르게 증가하고 있는것을 확인했습니다.
- 지역별로 아파트 실거래 가격지수를 확인해 봅니다.
1 2 | df6 = pd.read_csv('아파트실거래가격지수(2017.11=100).csv', encoding='CP949', skiprows=3, skipfooter=11) df6.head() |

- 마찬가지로 컬럼명과 날짜를 변경해줍니다.
1 2 3 4 5 6 7 8 | # Column 명 변경 column_name = ['시점', '전국', '서울', '수도권', '지방', '부산', '대구', '인천', '광주', '대전', '울산', '세종', '경기', '강원', '충북', '충남', '전북', '전남', '경북', '경남', '제주'] df6.columns=column_name # 시점을 datetime 으로 변경 df6['시점'] = pd.to_datetime(df6['시점']) df6.head() |
- 시각화를 진행합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | fig, ax = plt.subplots(figsize=(15,8)) df6.plot(x='시점', ax=ax) # 축 제거 ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # 기준점 표시 ax.annotate('2017.11=100', xy=('2017-11-01', 100.5), xytext=('2017-01-01', 120), arrowprops={'facecolor':'gray', 'arrowstyle':'-|>'}, horizontalalignment='center', fontsize=15, color='black') # x, y 축 label 표시 ax.set_xlabel('시점(단위 : 년)',loc='right') ax.set_ylabel('가격 지수 (2017.11=100)') # grid 설정 ax.grid(axis='y', ls=':') # 범례 설정 ax.legend(ncol=3, fontsize=12) plt.show() |
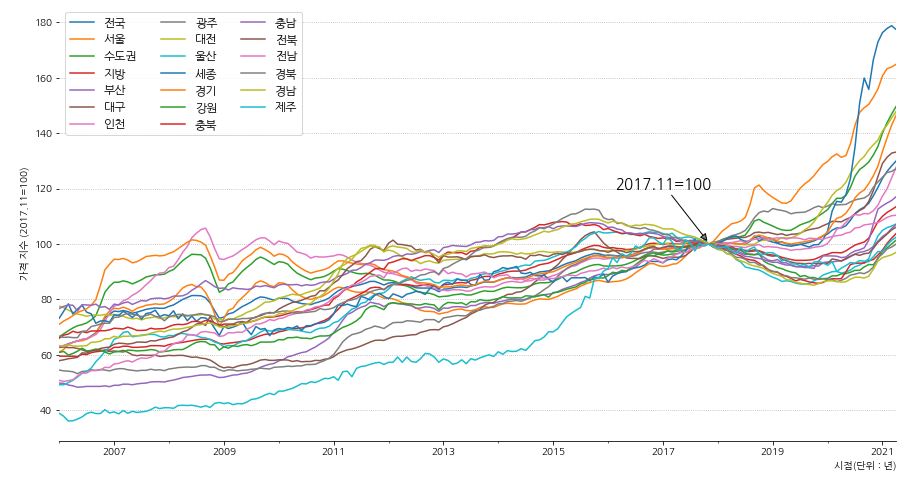
- 지역별로 나눠서 보니 남다른 상승폭을 가지고 있는 지역들이 몇개 보입니다.
- 지역을 크게 나눠서 확인해봅니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | fig, ax = plt.subplots(figsize=(15,8)) df6.plot(x='시점',y=['전국', '서울', '수도권', '지방'], ax=ax) # 축 제거 ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # 기준점 표시 ax.annotate('2017.11=100', xy=('2017-11-01', 100.5), xytext=('2017-01-01', 120), arrowprops={'facecolor':'gray', 'arrowstyle':'-|>'}, horizontalalignment='center', fontsize=15, color='black') # x, y 축 label 표시 ax.set_xlabel('시점(단위 : 년)',loc='right') ax.set_ylabel('가격 지수 (2017.11=100)') # grid 설정 ax.grid(axis='y', ls=':') # 범례 표시 ax.legend(ncol=4, loc='upper center', fontsize=12) plt.show() |
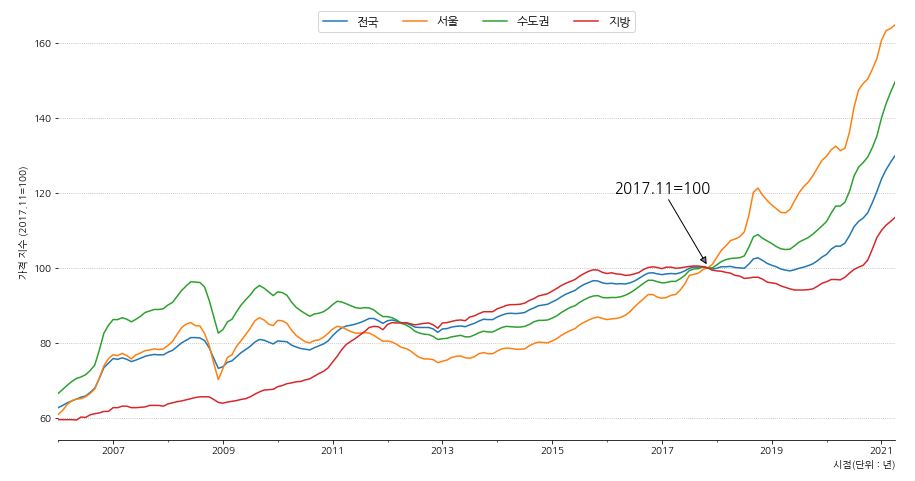
-
전국으로 봤을 때에도 상승세이지만, 지방에 비해 수도권의 상승세가 가파른 것을 확인할 수 있습니다.
-
특별시와 광역시로도 확인해봅니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | fig, ax = plt.subplots(figsize=(15,8)) df6.plot(x='시점',y=['서울', '인천', '대전', '대구', '광주', '부산', '울산'], ax=ax) # 축 제거 ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # 기준점 표시 ax.annotate('2017.11=100', xy=('2017-11-01', 100.5), xytext=('2017-01-01', 120), arrowprops={'facecolor':'gray', 'arrowstyle':'-|>'}, horizontalalignment='center', fontsize=15, color='black') # x, y 축 label 표시 ax.set_xlabel('시점(단위 : 년)',loc='right') ax.set_ylabel('가격 지수 (2017.11=100)') # grid 설정 ax.grid(axis='y', ls=':') # 범례 표시 ax.legend(ncol=4, loc='upper center', fontsize=12) plt.show() |
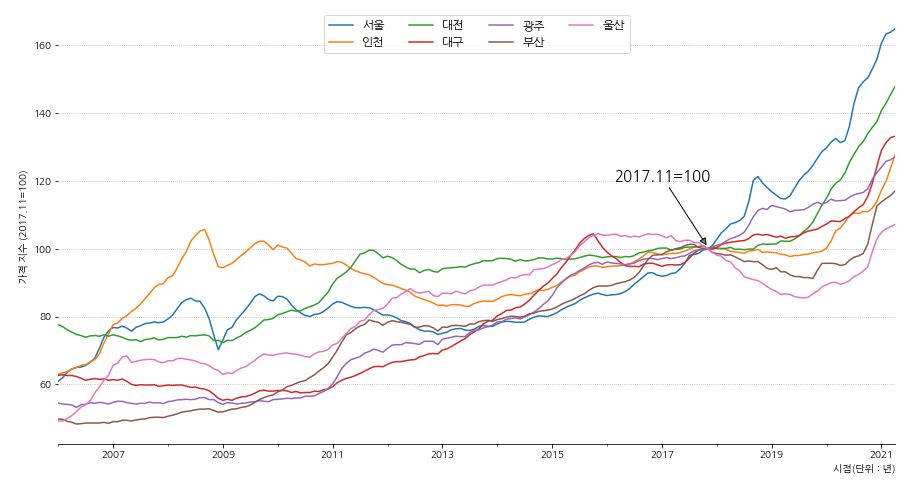
- 다른 광역시에 비해 서울의 아파트 가격이 급격하게 상승하고 있는 것을 볼 수 있습니다.
2.2.4. 가계대출 현황
- 부동산을 구매할 때, 일반적인 경우에는 대출이 필수적입니다.
- 부동산의 가격은 계속해서 상승하고 있으므로 대출의 현황도 살펴보도록 하겠습니다.
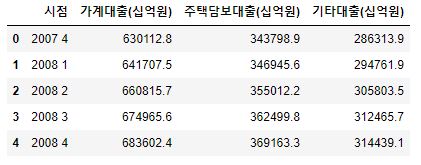
1 2 | df7 = pd.read_csv('가계대출현황.csv', encoding='CP949', skiprows=3, skipfooter=7, thousands=',') df7.head() |
- 컬럼명을 변경해줍니다.
- 가계대출 데이터는 분기별로 나누어져 있습니다.
- 가계대출에 주택담보대출이 포함되어있습니다.
1 2 3 4 5 | # column 명 변경 re_columns = ['시점', '가계대출(십억원)', '주택담보대출(십억원)', '기타대출(십억원)'] df7.columns = re_columns df7.head() |
- 가계 대출에서 주택담보대출이 차지하는 비중을 보기위해 시각화를 진행합니다.
- y축 ticklabel의 값을 조 단위로 변경해줍니다.
- x축 ticklabel의 값은 년도 뒷 2자리를 표현해주고 아래에 분기 Q를 붙여서 표기해줍니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | fig, ax= plt.subplots(figsize=(17,10)) # 축 제거 ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) df7[['시점', '가계대출(십억원)']].plot.bar(x = '시점', y='가계대출(십억원)', ax=ax, color='cornflowerblue', label='가계대출') df7[['시점', '주택담보대출(십억원)']].plot.bar(x = '시점', y='주택담보대출(십억원)', ax=ax, color='darkorange', label='주택담보대출') # y축 ticklabel 표시 변경 yticks = ax.get_yticks() ax.set_yticks(yticks) yticklabels = [f'{x//1000:.0f}조 원' for x in yticks] ax.set_yticklabels(yticklabels) # y축 ticklabel 표시 변경 xticks = ax.get_xticks() ax.set_xticks(xticks) xticklabels = [(f'{i[2:4]}'+'\n'+ f'{i[5:6]}Q') for i in df7['시점']] ax.set_xticklabels(xticklabels, rotation=0) # grid 설정 ax.grid(axis='y', linestyle=':', which='major') # y축 grid 추가 # x축 label 설정 ax.set_xlabel('시점(단위 : 년)',loc='right') # 범례 설정 ax.legend(ncol=2, fontsize=12) plt.show() |
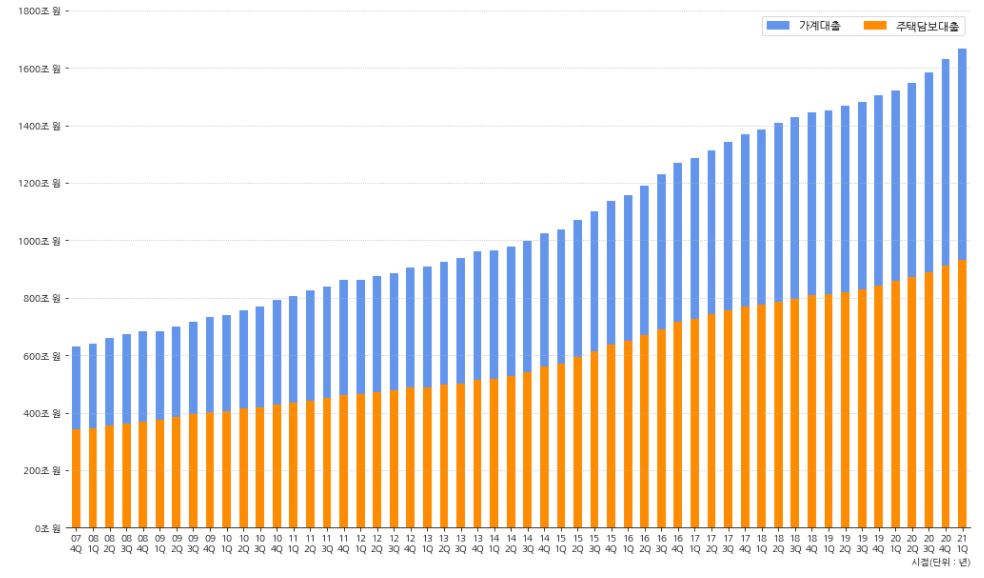
- 가계 대출과 주택담보대출은 지속적으로 늘어나고 있습니다.
- 그래프 상으로 가계대출 중 주택담보대출이 차지하는 비율은 일정해보입니다.
- 좀 더 자세하게 알아보기 위해 주택담보대출이 차지하는 비율을 나타내는 변수를 만들어 그래프에 추가해봅니다.
1 2 3 | # 가계대출 중 주택담보대출 비중 df7['주택담보대출비중(%)'] = round(df7['주택담보대출(십억원)']/df7['가계대출(십억원)']*100, 1) df7.head() |
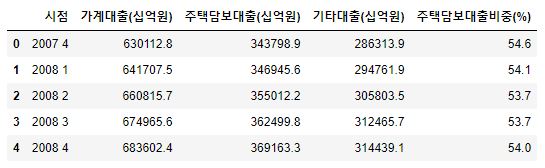
- 소수점 1자리 까지 나타내주고 그래프에 추가합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | fig, ax= plt.subplots(figsize=(17,10)) # 축 제거 ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) df7[['시점', '가계대출(십억원)']].plot.bar(x = '시점', y='가계대출(십억원)', ax=ax, color='lightgray', label='가계대출') df7[['시점', '주택담보대출(십억원)']].plot.bar(x = '시점', y='주택담보대출(십억원)', ax=ax, color='sandybrown', label='주택담보대출') # 오른쪽에 축 추가 후 주택담보대출 비중 변수 추가 ax_add = ax.twinx() ax_add.plot(df7['시점'], df7['주택담보대출비중(%)'],'o-', color='brown', label='주택담보대출 비중') ax_add.spines['left'].set_visible(False) ax_add.spines['right'].set_visible(False) ax_add.spines['top'].set_visible(False) ax_add.set_ylim(20,100) ax_add.axis(False) # 주택담보대출 비중 값 표시 for j in range(0, df7.shape[0], 6): ax_add.annotate(f'{df7["주택담보대출비중(%)"].iloc[j]}%', xy=(j, df7['주택담보대출비중(%)'].iloc[j]+0.1), xytext=(j, df7['주택담보대출비중(%)'].iloc[j]+2), arrowprops={'facecolor':'gray', 'arrowstyle':'-'}, horizontalalignment='center', fontsize=15, color='brown', alpha=0.8) ax_add.annotate(f'{df7["주택담보대출비중(%)"][df7.index[-1]]}%', xy=(df7.index[-1], df7['주택담보대출비중(%)'][df7.index[-1]]+0.1), xytext=(df7.index[-1], df7['주택담보대출비중(%)'][df7.index[-1]]+2), arrowprops={'facecolor':'gray', 'arrowstyle':'-'}, horizontalalignment='center', fontsize=15, color='brown', alpha=0.8) # y축 ticklabel 표시 변경 yticks = ax.get_yticks() ax.set_yticks(yticks) yticklabels = [f'{x//1000:.0f}조 원' for x in yticks] ax.set_yticklabels(yticklabels) ax.set_ylim(0,1800000) # x축 ticklabel 표시 변경 xticks = ax.get_xticks() ax.set_xticks(xticks) xticklabels = [(f'{i[2:4]}'+'\n'+ f'{i[5:6]}Q') for i in df7['시점']] ax.set_xticklabels(xticklabels, rotation=0) # grid 설정 ax.grid(axis='y', linestyle=':', which='major') # y축 grid 추가 # x축 label 설정 ax.set_xlabel('시점(단위 : 년)',loc='right') # 범례 설정 ax.legend(ncol=2, loc='upper center', fontsize=13) ax_add.legend(loc='center left', bbox_to_anchor=(0.04, 0.55), fontsize=13) plt.show() |
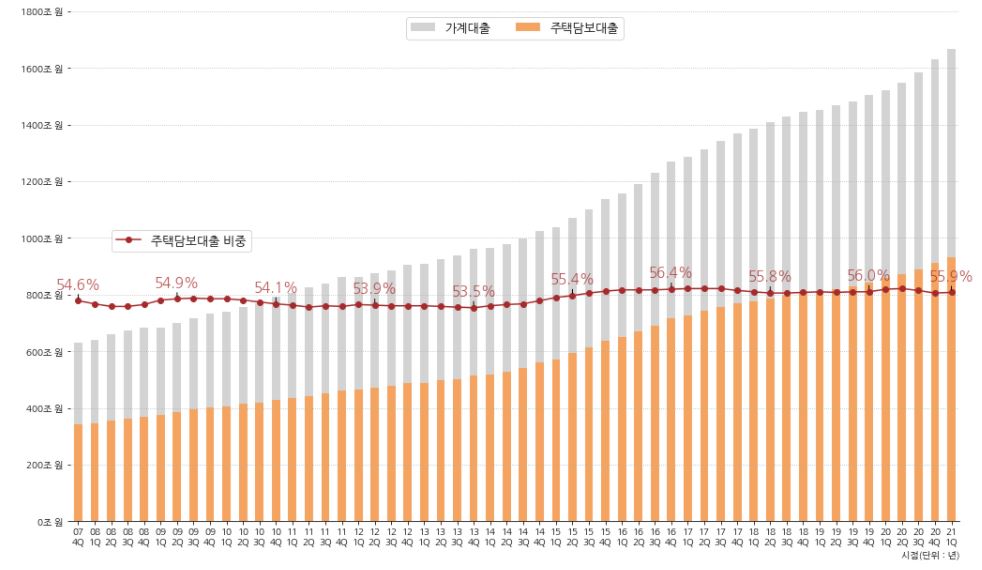
- 가계대출이 늘어나는만큼 주택담보대출도 늘어나고있습니다.
- 이와같이 일정한 증가율을 보이는 이유는 금융당국에서 가계부채 증가율을 관리하고 있기 때문입니다.
- 최근에는 빠르게 증가하는 가계부채로 인해 대출을 중단하는 등 규제를 시행하고 있습니다. 관련기사
2.3. 혼인율 및 출산율과 부동산 가격의 관계
- 인구동향 데이터와 부동산 데이터를 함께 그리고 비교해보도록 합니다.
- 인구동향 데이터에서
조혼인율과합계출산율을 사용하고 부동산 데이터에서는주택매매가격 총지수와주택전세가격 총지수를 사용합니다. - 부동산 데이터는 1986년~ 2020년 까지의 데이터만 존재하므로 시점을 맞춰줍니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | fig, ax = plt.subplots(figsize=(17,10)) df4.plot(x='시점',y='총지수', ax=ax, color='tab:green', label='주택매매가격지수') df5.plot(x='시점', y='총지수', ax=ax, color='tab:brown', label='주택전세가격지수') ax_add = ax.twinx() df1.plot(x='시점', y='합계출산율(명)', ax=ax_add, marker='.', color='tab:blue') ax_add2 = ax.twinx() df1.plot(x='시점', y='조혼인율(천명당)', ax=ax_add2, marker='.', color='tab:orange') # 축 제거 ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) ax_add.spines['left'].set_visible(False) ax_add.spines['right'].set_visible(False) ax_add.spines['top'].set_visible(False) ax_add.axis(False) ax_add2.spines['left'].set_visible(False) ax_add2.spines['right'].set_visible(False) ax_add2.spines['top'].set_visible(False) ax_add2.axis(False) # 합계출산율과 조혼인율의 값 표시 for i in range(df1[df1['시점'] == '1986-01-01'].index[0], df1[df1['시점'] == '2020-01-01'].index[0],3): ax_add.text(df1['시점'][i], df1['합계출산율(명)'][i]+0.1, f"{df1['합계출산율(명)'][i]:.2f}명", fontsize=13, ha='center') for i in range(df1[df1['시점'] == '1986-01-01'].index[0], df1[df1['시점'] == '2020-01-01'].index[0],3): ax_add2.text(df1['시점'][i], df1['조혼인율(천명당)'][i]+0.2, f"{df1['조혼인율(천명당)'][i]:.1f}건", fontsize=13, ha='center') # x, y 축 범위 설정 ax.set_ylim(0,120) ax_add.set_xlim('1986-01-01', '2020-01-01') ax_add.set_ylim(0,5) ax_add2.set_xlim('1986-01-01', '2020-01-01') ax_add2.set_ylim(0,12) # x, y 축 label 표시 ax.set_xlabel('시점(단위 : 년)',loc='right') ax.set_ylabel('가격 지수 (2019.01=100)') # grid 설정 ax.grid(axis='y',ls=':') # 범례 설정 ax.legend(bbox_to_anchor=(0.9,0.8), fontsize=12) ax_add.legend(bbox_to_anchor=(0.4,0.25), fontsize=12) ax_add2.legend(bbox_to_anchor=(0.32,0.8), fontsize=12) plt.show() |
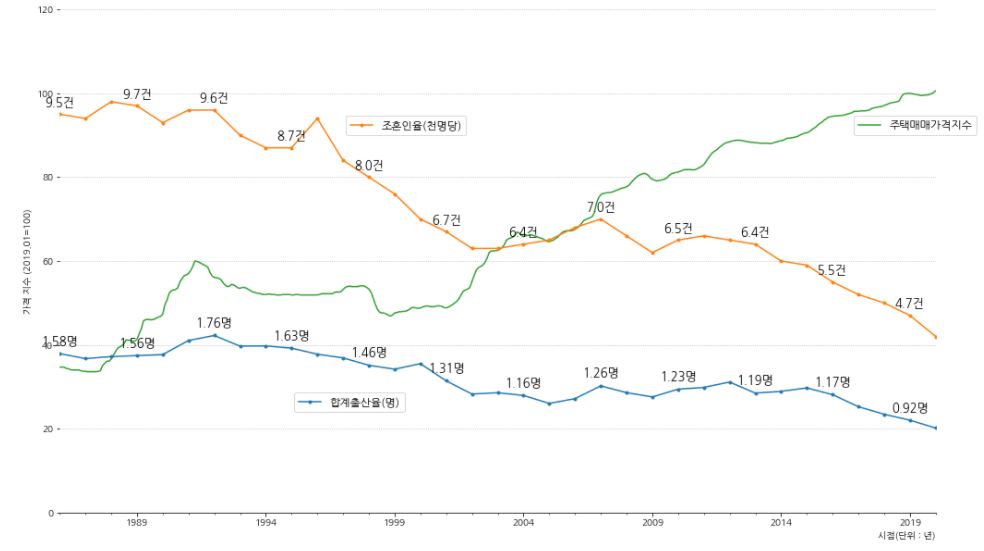
- 일반적으로 합계출산율은 혼인율이 감소하면서 함께 줄어든다고 생각할 수 있습니다.
- 혼인율과 부동산 가격 지수들을 비교하면 두 변수가 반비례 관계로 보이긴 합니다.
3. 결론
-
큰 흐름으로 혼인율은 우하향 하고 있고 부동산 가격은 우상향 하고 있습니다.
-
하지만 부동산 가격이 내려간다고해서 혼인율과 출산율이 올라간다는 근거가 부족하다고 생각합니다.
-
그렇기 때문에 “집 값이 비싸서 결혼을 하기 부담스럽다.” 라는 말은 조금 애매한 부분이 있습니다.
-
실제로 전세자금대출이나 주택구입자금대출은 신혼부부가 유리한 면도 있기 때문입니다.
-
하지만 수 많은 사람들이 느끼고 있기 때문에 원인 중 하나라고 볼 수 있을 것 같습니다.
-
더 나아가 생각해야 할 점은 “과연 부동산 가격이 안정화 되서 혼인율이 올라가면 저출산 문제가 해결될까?” 입니다.
4. 느낀점
저출산이라는 문제를 알아보기 위해 시작했지만 사회 문제는 여러가지 문제들이 복합적으로 얽혀있어 단순히 부동산만의 문제라고 보기에는 애매하다는 결론이 나왔습니다. 인구와 부동산 또한 각 분야의 지식을 갖추고 있어야 더 많은 관련된 자료를 확인 할 수 있는 것 같습니다.