추천 시스템(Recommender System)(2) 추천 시스템 알고리즘
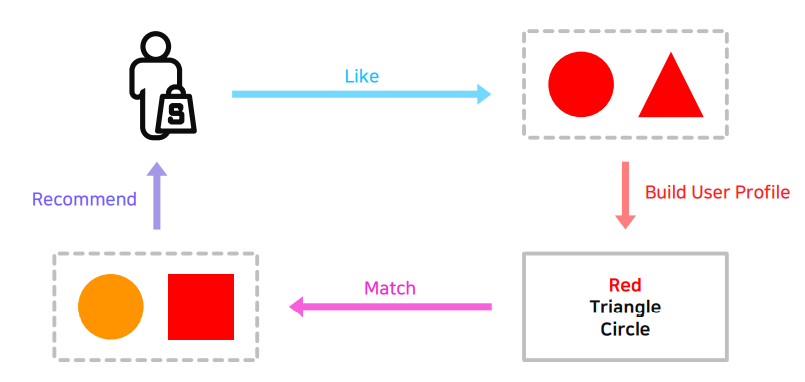
Content-based Recommmendation
유저가 선호하는 아이템을 기반으로 해당 아이템과 유사한 아이템을 추천해주는 방법
- User A가 과거에 선호한 아이템과 비슷한 아이템을 User A에게 추천
Collaborative Filtering(CF)
다수의 유저들로 부터 얻은 정보를 이용해 유저의 관심사를 예측하는 방법
-
User-Item 행렬을 이용해 user 혹은 item 간의 유사도를 구해 예측
(ex 유저 A와 비슷한 취향을 가진 유저들이 선호하는 아이템을 추천)
-
CF는 Memory-Based(Neighborhood-based) 와 Model-based 로 나눌 수 있다
Memory-Based(Neighborhood-based) Collaborative Filtering
- 유저가 아이템에 부여할 평점을 예측하는 것
- 아이템이나 유저가 늘어날수록 확장성이 떨어짐 (아이템 i에 대한 평점을 예측하기 위해서는 아이템 i에 대해 평가한 모든 유저와의 유사도를 구해야하기 때문)
- 주어진 Interaction 데이터가 적으면 성능이 저하됨
- sparsity ratio 가 99.5%를 넘지 않아야 됨
- sparsity ratio : 행렬 전체 원소 중 비어있는 원소의 비율
- User-based CF, Item-based CF 로 나뉜다
User-based CF(UBCF)
- 유저간 유사도를 구한 뒤, 타겟 유저와 유사도가 높은 유저들이 선호하는 아이템을 추천
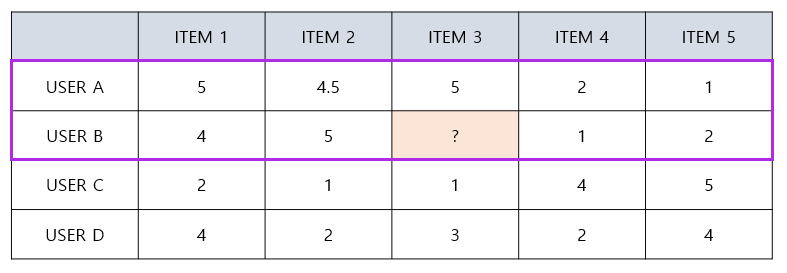
- 직관적으로 User B는 User A와 비슷한 취향을 가질 것으로 보임
- 그렇기 때문에 ITEM 3에 대한 User B의 선호도는 User A와 비슷하게 높은 선호도를 나타낼 것으로 예측
Item-based CF(IBCF)
- 아이템간 유사도를 구한 뒤, 타겟 아이템과 유사도가 높은 아이템 중 선호도가 큰 아이템을 추천
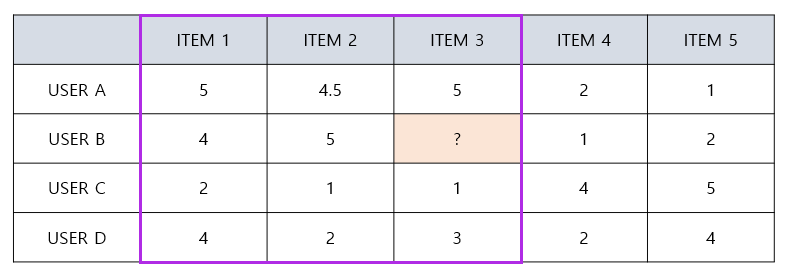
- 직관적으로 ITEM 1과 ITEM 2는 높은 유사도를 가지고 있다고 볼 수 있음
- ITEM 3도 ITEM 1과 ITEM 2와 높은 유사도를 가질 것이라고 예측할 수 있음
K-Nearest Neighbors CF(KNN CF)
- 아이템 i 에 속한 유저 가운데 유저 u와 가장 유사한 K명의 유저(KNN)를 이용한 예측
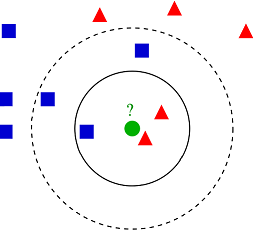
- ex) K=1 일 때, 가장 유사한 유저 1명의 평점 데이터를 이용해 예측
Rating Prediction
평점을 예측하는 방법의 종류
전체 유저 : U
전체 아이템 : I
유저 u의 아이템 i에 대한 평점 : $\hat{r}(u,i)$
아이템 i에 대한 평점이 있으면서 유저 u와 유사한 유저들의 집합 : $\Omega{i}$
유저 u가 평가한 아이템들의 집합 : $\Phi_{u}$
UBCF - Absolute Rating(Average)
- 해당 아이템을 사용한 유저들의 rating 평균
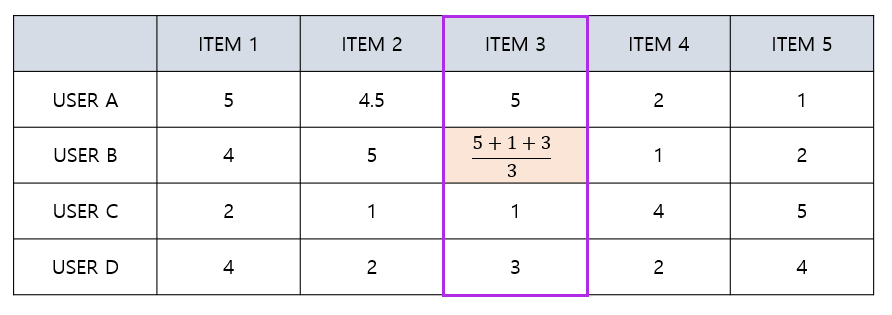
$$ \hat{r}(u,i)=\frac{\sum_{u’\in \Omega_{i}}r(u’,i)}{\Omega_{i}} $$
UBCF - Absolute Rating(Weighted Average)
- 유저 간의 유사도 값을 가중치(weight)로 사용해 rating 평균
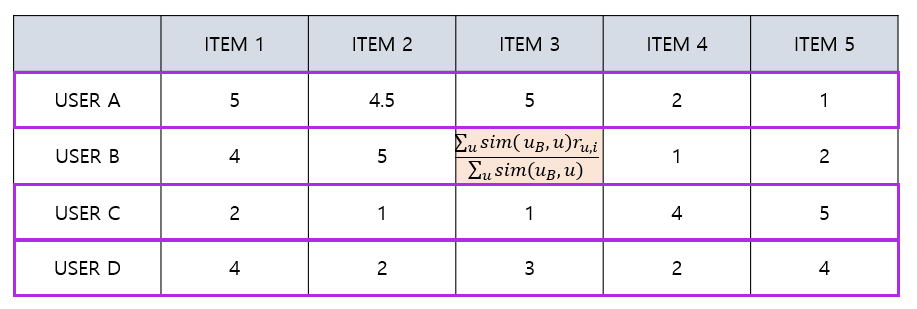
$$ \hat{r}(u,i)=\frac{\sum_{u’\in \Omega_{i}}sim(u,u’)r(u’,i)}{\sum_{u’\in \Omega_{i}}sim(u,u’)} $$
- User B와의 유사도가 A(0.95), C(0.6), D(0.9) 라고 가정한다면 다음과 같이 계산 할 수 있다 $$ \frac{0.955 + 0.61 + 0.85*3}{0.95 + 0.6 + 0.85}=3.3 $$
Absolute Rating 문제점
- 하지만 위와 같은 방법은 큰 문제점이 있음
- 유저마다 평점을 주는 기준이 다름 (전체적으로 평점을 높게주는 유저도 있고 낮게 주는 유저도 있음)
- 그렇기 때문에 유저의 평균을 기준으로 편차(Deviation)를 사용
$$ dev(u,i)=r(u,i) - \overline{r_{u}}$$
-
모든 평점 데이터를 deviation 값으로 바꾼 뒤 deviation을 예측한 후 평균을 더해준다
-
Relative Rating 최종 수식 $$ \hat{r}(u,i)=\overline{r_u} + \frac{\sum_{u’\in \Omega_{i}}sim(u,u’){r(u’,i)-\overline{r_{u’}}}}{\sum_{u’\in \Omega_{i}}sim(u,u’)} $$
IBCF - Relative Rating
- IBCF 의 경우에도 deviation과 weight average 를 결합하면 다음과 같이 구할 수 있다
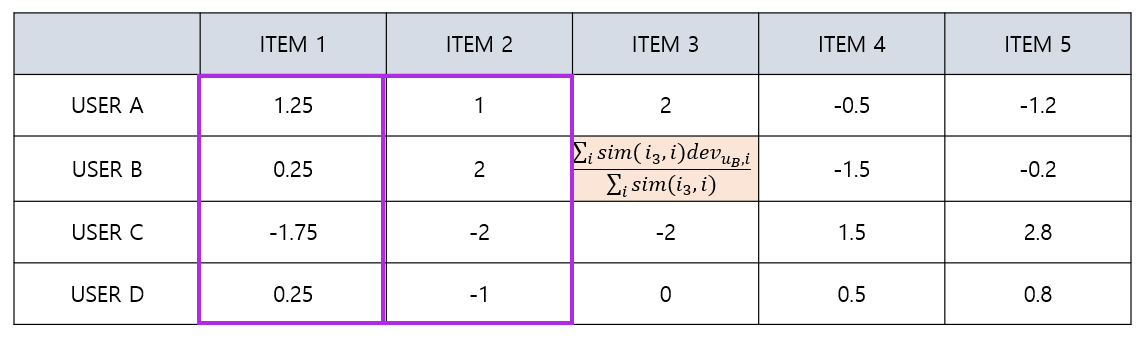
$$ \hat{r}(u,i)=\overline{r_i} + \frac{\sum_{i’\in \Phi_{u}}sim(i,i’){r(u,i’)-\overline{r_{i’}}}}{\sum_{i’\in \Phi_{u}}sim(i,i’)} $$
Top-N Recommendation
- 타겟 유저에 대한 예측 평점을 구했다면 높은 순서로 정렬 후 상위 N개를 뽑아 추천할 수 있다
Model-Based Collaborative Filtering
- 단순히 유사성을 비교하는 것이 아닌 데이터에 내재한 패턴을 이용해 추천하는 CF 기법
- Matrix Factorization(MF) 기법이 가장 많이 사용 됨
- 학습된 모델을 사용해 추천하기 때문에 서빙 속도가 빠름
- sparse 한 데이터에서도 좋은 성능
- 유저, 아이템 수가 많아져도 좋은 추천 성능
- Overfitting을 방지할 수 있음
Matrix Factorization (MF)
- User-Item 행렬(R)을 저차원의 User와 Item 의 latent factor 행렬 곱으로 분해하는 방법
- R을 P와 Q로 분해하여 R와 최대한 유사하게 추론
$$ R \approx P \times Q^{T} = \hat{R} $$
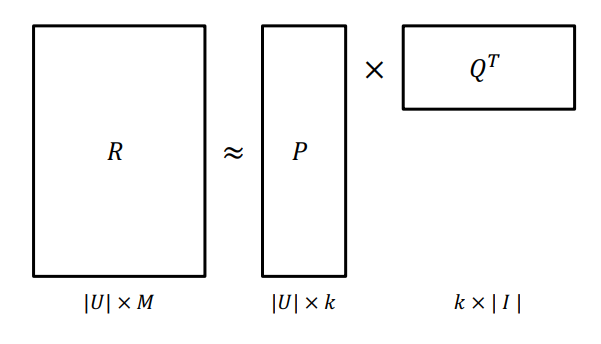
- 관측된 선호도 정보를 활용해 관측되지 않은 선호도를 예측하는 모델을 만드는 것이 목표
위 내용은 Boostcamp 강의를 요약했습니다.