HDFS(Hadoop Distributed File System) 하둡 분산 파일 시스템
Hadoop 생태계
HDFS (Hadoop Distributed File System)
- 대용량 파일을 다루기 위해 사용되며 대용량 파일을 작은 조각으로 나누어 클러스터 전체에 분산시키데에 최적화 되어 있음
- 대용량 데이터를 데이터 블록(기본값 128MB)들로 쪼갬
- 쪼갠 블록들을 여러 범용 컴퓨터에 저장
- 블록을 처리하는 컴퓨터가 해당 블록이 저장된 곳이랑 물리적으로 가까운 거리에 있도록 조정
- 모든 블록의 복사본이 노드에 퍼져있기 때문에 데이터 손실 방지
- 크게
Name Node와Data Node로 이루어져 있음 MapReduce를 이용해 데이터 처리
Name Node
- 메타 데이터 관리(파일 이름, 가상 디렉토리 구조, 블록 및 블록 사본의 위치 등)
- Data Node 와 상황 공유를 하며 변경 사항이 생기면 Name Node 에 저장됨
Edit log에 수정, 생성, 저장 등의 정보가 기록됨- 한번에 하나의 Name Node만 사용됨
- 빠른 검색을 위해 메모리에서 관리
Data Node
- 실제 파일의 블록을 저장하고 있는 Node
HDFS Architecture
동작원리 예시
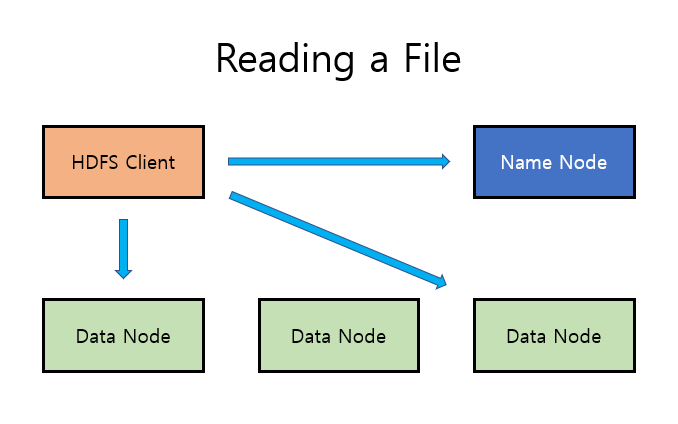
- 파일을 읽을 때, Client는 Name Node로 부터 어떤 블록을 어디에서 찾아야할지 정보를 얻은 후 데이터를 찾아감
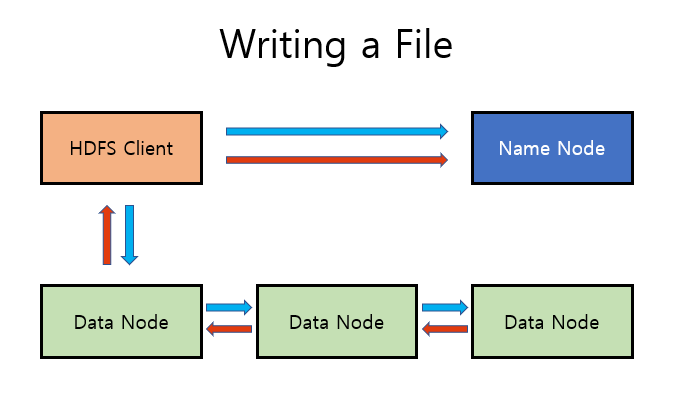
- 파일을 쓸 때, Client는 Name Node 로 부터 어디에 파일을 저장할지 정보를 받음
- Client 는 정해진 Data Node 에 파일을 전달함
- Data Node는 주변의 Data Node 에게 복사본을 전달함
- 파일의 위치와 복사본의 위치를 다시 전달해 Client를 통해 Name Node 에게 알려줌
Name Node Resilience
Name Node가 손상되어 데이터의 손실이 나는 것을 방지하는 방법
- 지속적인 메타데이터 백업
- Name Node 가 백업 저장소와 디스크에 동시에 작업할 수 있도록 구성
- 하지만 어느저도의 정보 손실이 있을 수도 있음
- Secondary Name Node
- Name Node 의 Edit log를 복사해 가지고 있음
- Name Node 의 기능을 수행하지는 않음
- HDFS Federation
- HDFS는 대용량 파일을 다루는데 최적화 되어 있지만 많은 수의 작은 파일이 있다면 메모리 사용량이 증가해 문제가 될 수 있음
- 디렉토리 단위로 Name Node를 등록해 사용
- 각 Name Node가 독립적으로 관리
- HDFS High Availability
- 공유 저장소에 Edit log를 공유
- Name Node에 문제가 생기면 ‘동적 예비 Name Node’가 업무를 이어받음
- Zookeeper를 사용해 어떤 Name Node와 소통해야 하는지 알아내고 하나의 Name Node만 사용하도록 통제